介绍如果搭建redis集群,以及如何对集群进行扩展与收缩
前言
为了提高缓存服务器的写请求处理能力与数据存储能力可使用redis集群,根据实际业务情况对集群进行扩展与收缩
准备工作
由于机器的限制,此文章中的redis实例都是在一台机器上启动的,通过不同的port来模拟不同的redis实例。
[root@vagrant redis-6386]# ps -ef|grep redis
root 2943 1 0 15:29 ? 00:00:01 ./redis-server *:6381 [cluster]
root 2952 1 0 15:39 ? 00:00:00 ./redis-server *:6382 [cluster]
root 2960 1 0 15:40 ? 00:00:00 ./redis-server *:6383 [cluster]
root 2968 1 0 15:40 ? 00:00:00 ./redis-server *:6384 [cluster]
root 2976 1 0 15:41 ? 00:00:00 ./redis-server *:6385 [cluster]
root 2984 1 0 15:42 ? 00:00:00 ./redis-server *:6386 [cluster]
数据分布
数据分区
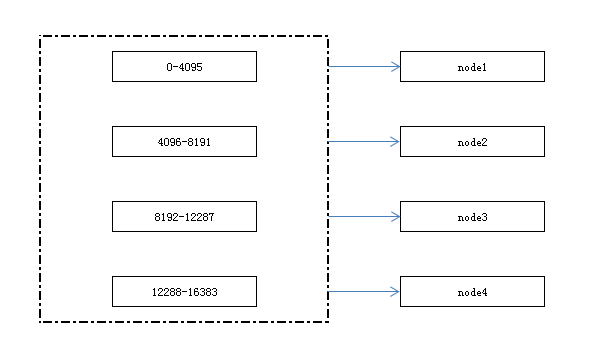
redis集群采用虚拟槽分区,所有的键根据哈希函数映射到[0-16383]整数槽内,计算公式:slot=CRC16(key)&16383,每一个节点负责维护一部分槽以及槽所映射的键值数据,有如下一些特点:
- 解耦数据和节点之间的关系,简化了节点扩容和收缩难度
- 节点自身维护槽的映射关系,不需要客户端或者代理服务维护槽分区元数据
- 支持节点、槽、键之间的映射查询,用于数据路由、在线伸缩等场景
集群功能限制
不同于单机环境,集群环境有如下一些限制:
集群客户端支持下面的操作么?
- key批量操作支持有限。如mset、mget,目前只支持具有相同slot值的key执行批量操作。对于映射为不同slot值的key由于执行mget、mget等操作可能存在于多个节点上因此不被支持
- key事务操作支持有限。同理只支持多key在同一节点上的事务操作,当多个key分布在不同的节点上时无法使用事务功能
- key作为数据分区的最小粒度,因此不能将一个大的键值对象如hash、list等映射到不同的节点
- 不支持多数据库空间。单机下的Redis可以支持16个数据库,集群模式下只能使用一个数据库空间,即db0
- 复制结构只支持一层,从节点只能复制主节点,不支持嵌套树状复制结构
集群搭建
节点准备
为了搭建集群需要准备多个redis节点,通常至少需要6个(3主3从)才能组建一个高可用的集群。节点配置同单机模式,除了以下几个相关的配置:
#开启集群模式
cluster-enabled yes
#节点超时时间,单位毫秒
cluster-node-timeout 15000
#集群配置文件(nodes-{port}.conf)
cluster-config-file "nodes-6379.conf"
在启动节点时,如果没有配置文件则会根据cluster-config-file自动创建一个,否则使用配置文件来初始化集群信息。redis会自动维护此配置文件,不需要手动修改,以免错误。配置文件中的节点id在集群初始化的时候会创建一次,之后会一直重用。
#配置文件
[root@vagrant redis-6381]# cat nodes-6381.conf
da2bd0c5419300bbe390dab920872aee71ae7d1d :0@0 myself,master - 0 0 0 connected
vars currentEpoch 0 lastVoteEpoch 0
#集群节点状态
[root@vagrant redis-6381]# ./redis-cli -p 6381 cluster nodes
da2bd0c5419300bbe390dab920872aee71ae7d1d :6381@16381 myself,master - 0 0 0 connected
手动部署
节点握手
当所有节点都启动后,彼此之间是不知道其它节点的存在的。可以在任意节点上执行cluster meet {ip} {port}命令,握手状态会通过消息在集群内传播,这样其他节点会自动发现新节点并发起握手流程。
[root@vagrant redis-6386]# ./redis-cli -p 6381 cluster meet 127.0.0.1 6382
OK
[root@vagrant redis-6386]# ./redis-cli -p 6381 cluster meet 127.0.0.1 6383
OK
[root@vagrant redis-6386]# ./redis-cli -p 6381 cluster meet 127.0.0.1 6384
OK
[root@vagrant redis-6386]# ./redis-cli -p 6381 cluster meet 127.0.0.1 6385
OK
[root@vagrant redis-6386]# ./redis-cli -p 6381 cluster meet 127.0.0.1 6386
OK
执行命令后,可在任意节点查看集群节点状态。
#6381
[root@vagrant redis-6386]# ./redis-cli -p 6381 cluster nodes
75cb527086abcb65ab2dcf7f96cc539d1293a6a3 127.0.0.1:6383@16383 master - 0 1539503506009 2 connected
9291db5efb3254f60ec828525dfa9f62983be18b 127.0.0.1:6386@16386 master - 0 1539503502994 5 connected
02a0f13dd1455bd849afd268b5d0bfc82a28cbf8 127.0.0.1:6385@16385 master - 0 1539503503000 4 connected
edbbe9a0fb92076ac4bf896337ec7c5237124b86 127.0.0.1:6384@16384 master - 0 1539503505005 0 connected
da2bd0c5419300bbe390dab920872aee71ae7d1d 127.0.0.1:6381@16381 myself,master - 0 1539503502000 3 connected
6c1722030a1e5fc1fd0d076819dad662a4941db1 127.0.0.1:6382@16382 master - 0 1539503505000 1 connected
#6386
[root@vagrant redis-6386]# ./redis-cli -p 6386 cluster nodes
edbbe9a0fb92076ac4bf896337ec7c5237124b86 127.0.0.1:6384@16384 master - 0 1539503942475 0 connected
02a0f13dd1455bd849afd268b5d0bfc82a28cbf8 127.0.0.1:6385@16385 master - 0 1539503943000 4 connected
75cb527086abcb65ab2dcf7f96cc539d1293a6a3 127.0.0.1:6383@16383 master - 0 1539503941469 2 connected
9291db5efb3254f60ec828525dfa9f62983be18b 127.0.0.1:6386@16386 myself,master - 0 1539503942000 5 connected
6c1722030a1e5fc1fd0d076819dad662a4941db1 127.0.0.1:6382@16382 master - 0 1539503943480 1 connected
da2bd0c5419300bbe390dab920872aee71ae7d1d 127.0.0.1:6381@16381 master - 0 1539503940460 3 connected
节点槽分配
在节点完成互相握手后,集群还是不能使用的,只有当16384个槽被完全分配到节点上时,集群才进入可使用状态。
#集群信息
[root@vagrant redis-6386]# ./redis-cli -p 6381 cluster info
cluster_state:fail
cluster_slots_assigned:0
cluster_slots_ok:0
cluster_slots_pfail:0
cluster_slots_fail:0
cluster_known_nodes:6
cluster_size:0
...
#不能使用集群
[root@vagrant redis-6386]# ./redis-cli -p 6381 set a 1
(error) CLUSTERDOWN Hash slot not served
槽(slot)是redis集群中数据的分区单位,每个key经过CRC16计算会映射到一个固定的槽,只有节点分配了槽,才能响应和这些槽关联的键命令。通过cluster addslots将槽平均分配给3个节点。
[root@vagrant redis-6386]# ./redis-cli -p 6381 cluster addslots {0..5461}
OK
[root@vagrant redis-6386]# ./redis-cli -p 6382 cluster addslots {5462..10922}
OK
[root@vagrant redis-6386]# ./redis-cli -p 6383 cluster addslots {10923..16383}
OK
#集群信息
[root@vagrant redis-6386]# ./redis-cli -p 6383 cluster info
cluster_state:ok
cluster_slots_assigned:16384
cluster_slots_ok:16384
cluster_slots_pfail:0
cluster_slots_fail:0
cluster_known_nodes:6
cluster_size:3
...
可看到集群已经变为可使用状态,测试使用集群设置键值对
#在6381执行提示moved信息,因为'a'计算出来的槽为15495,在6383上
[root@vagrant redis-6386]# ./redis-cli -p 6381 set a 1
(error) MOVED 15495 127.0.0.1:6383
#命令增加'-c'代表自动进行命令转向,在6383执行
[root@vagrant redis-6386]# ./redis-cli -p 6381 -c set a 1
OK
[root@vagrant redis-6386]# ./redis-cli -p 6381 -c get a
"1"
查看槽与节点的分配关系
#集群节点状态
[root@vagrant redis-6386]# ./redis-cli -p 6383 cluster nodes
923c5d325b6dcbcca94276195206e24cdd37039b 127.0.0.1:6382@16382 master - 0 1539508163000 1 connected 5462-10922
edbbe9a0fb92076ac4bf896337ec7c5237124b86 127.0.0.1:6384@16384 master - 0 1539508165000 0 connected
b9cb94e45c16cb2aadc60eefc29bee386b7a9ef7 127.0.0.1:6381@16381 master - 0 1539508166253 7 connected 0-5461
02a0f13dd1455bd849afd268b5d0bfc82a28cbf8 127.0.0.1:6385@16385 master - 0 1539508165248 4 connected
9291db5efb3254f60ec828525dfa9f62983be18b 127.0.0.1:6386@16386 master - 0 1539508164244 5 connected
0235798b70ba10533e04d3cc7c6e2345f4481d9f 127.0.0.1:6383@16383 myself,master - 0 1539508164000 2 connected 10923-16383
目前还有3个节点没有使用,为了实现集群的高可用性,这3个节点作为槽节点的从节点,当出现故障时进行故障转移。集群模式下,reids节点角色分为主节点和从节点,首次启动的节点和被分配槽的节点都是主节点,从节点负责复制主节点槽信息和相关的数据。使用cluster replicate {nodeId}命令让一个节点成为某个主节点的从节点。
[root@vagrant redis-6386]# ./redis-cli -p 6384 cluster replicate b9cb94e45c16cb2aadc60eefc29bee386b7a9ef7
OK
[root@vagrant redis-6386]# ./redis-cli -p 6385 cluster replicate 923c5d325b6dcbcca94276195206e24cdd37039b
OK
[root@vagrant redis-6386]# ./redis-cli -p 6386 cluster replicate 0235798b70ba10533e04d3cc7c6e2345f4481d9f
OK
查看集群节点状态和复制关系
[root@vagrant redis-6386]# ./redis-cli -p 6381 cluster nodes
02a0f13dd1455bd849afd268b5d0bfc82a28cbf8 127.0.0.1:6385@16385 slave 923c5d325b6dcbcca94276195206e24cdd37039b 0 1539509091000 4 connd
923c5d325b6dcbcca94276195206e24cdd37039b 127.0.0.1:6382@16382 master - 0 1539509093853 1 connected 5462-10922
0235798b70ba10533e04d3cc7c6e2345f4481d9f 127.0.0.1:6383@16383 master - 0 1539509091000 2 connected 10923-16383
9291db5efb3254f60ec828525dfa9f62983be18b 127.0.0.1:6386@16386 slave 0235798b70ba10533e04d3cc7c6e2345f4481d9f 0 1539509092849 5 connd
b9cb94e45c16cb2aadc60eefc29bee386b7a9ef7 127.0.0.1:6381@16381 myself,master - 0 1539509093000 7 connected 0-5461
edbbe9a0fb92076ac4bf896337ec7c5237124b86 127.0.0.1:6384@16384 slave b9cb94e45c16cb2aadc60eefc29bee386b7a9ef7 0 15395090920
自动部署
对于集群的维护,如果使用手动执行相关命令的话,比较费时且很容易出现错误。可以通过redis提供的redis-trib.rb工具来进行集群的管理。
Tips:在最新的redis版本里,已经不再支持redis-trib.rb工具,可以直接使用redis-cli --cluster来进行集群的管理,使用方式同redis-trib.rb
ruby环境
redis-trib.rb是采用Ruby实现的Redis集群管理工具,所以使用前需要安装Ruby依赖环境。
安装ruby
[root@vagrant /]# cd /bmsource/
[root@vagrant bmsource]# wget https://cache.ruby-lang.org/pub/ruby/2.3/ruby-2.3.1.tar.gz
[root@vagrant bmsource]# tar xvf ruby-2.3.1.tar.gz
[root@vagrant bmsource]# cd ruby-2.3.1
[root@vagrant ruby-2.3.1]# ./configure -prefix=/usr/local/bin/
[root@vagrant ruby-2.3.1]# make
[root@vagrant ruby-2.3.1]# make install
#复制可执行文件到/usr/local/bin/
[root@vagrant ruby-2.3.1]# cd /usr/local/bin/bin
[root@vagrant bin]# cp ruby /usr/local/bin/
[root@vagrant bin]# cp gem /usr/local/bin/
安装ruby gem redis依赖
root@vagrant bin]# cd /bmsource/
[root@vagrant bmsource]# wget http://rubygems.org/downloads/redis-3.3.0.gem
[root@vagrant bmsource]# gem install -l redis-3.3.0.gem
#查看包是否已安装
[root@vagrant bmsource]# gem list
执行redis-trib.rb命令确认环境是否正确
[root@vagrant bmsource]# cd /usr/local/bin/redis-6381/
[root@vagrant redis-6381]# ./redis-trib.rb
Usage: redis-trib <command> <options> <arguments ...>
create host1:port1 ... hostN:portN
--replicas <arg>
...
节点准备
同手动部署,首先准备6个集群节点。
[root@vagrant redis-6382]# ps -ef|grep redis
root 18040 1 0 18:22 ? 00:00:00 ./redis-server *:6381 [cluster]
root 18049 1 0 18:23 ? 00:00:00 ./redis-server *:6383 [cluster]
root 18054 1 0 18:23 ? 00:00:00 ./redis-server *:6384 [cluster]
root 18059 1 0 18:23 ? 00:00:00 ./redis-server *:6385 [cluster]
root 18064 1 0 18:23 ? 00:00:00 ./redis-server *:6386 [cluster]
root 18071 1 0 18:23 ? 00:00:00 ./redis-server *:6382 [cluster]
集群创建
使用redis-trib.rb create创建集群,--replicas 1用于指定主节点拥有的从节点个数
[root@vagrant redis-6382]# ./redis-trib.rb create --replicas 1 127.0.0.1:6381 127.0.0.1:6382 127.0.0.1:6383 127.0.0.1:6384 127.0.0.1:6385 127.0.0.1:6386
创建程序首先会给出主节点,从节点,槽的分配概况
>>> Creating cluster
>>> Performing hash slots allocation on 6 nodes...
Using 3 masters:
127.0.0.1:6381
127.0.0.1:6382
127.0.0.1:6383
Adding replica 127.0.0.1:6385 to 127.0.0.1:6381
Adding replica 127.0.0.1:6386 to 127.0.0.1:6382
Adding replica 127.0.0.1:6384 to 127.0.0.1:6383
>>> Trying to optimize slaves allocation for anti-affinity
[WARNING] Some slaves are in the same host as their master
M: 9b53bc798f30f0c3aad64ae787ef97bfb520ed62 127.0.0.1:6381
slots:0-5460 (5461 slots) master
M: e19b36f039d4c56db0e48c9ffda0d00555a9576a 127.0.0.1:6382
slots:5461-10922 (5462 slots) master
M: 0113a3532640fe678bd652bac626e4fc2fc32916 127.0.0.1:6383
slots:10923-16383 (5461 slots) master
S: f9a65ed5171b9a66e70b4a12474386c4f9b47e35 127.0.0.1:6384
replicates e19b36f039d4c56db0e48c9ffda0d00555a9576a
S: 4010a79852155581fffc9e632398898619a5db90 127.0.0.1:6385
replicates 0113a3532640fe678bd652bac626e4fc2fc32916
S: c9a2731b7db540b7937b4bde854be8a0817258f0 127.0.0.1:6386
replicates 9b53bc798f30f0c3aad64ae787ef97bfb520ed62
Can I set the above configuration? (type 'yes' to accept): yes
查看分配情况,如果觉得没问题可以输入yes来执行实际分配
>>> Nodes configuration updated
>>> Assign a different config epoch to each node
>>> Sending CLUSTER MEET messages to join the cluster
Waiting for the cluster to join.......
>>> Performing Cluster Check (using node 127.0.0.1:6381)
M: 9b53bc798f30f0c3aad64ae787ef97bfb520ed62 127.0.0.1:6381
slots:0-5460 (5461 slots) master
1 additional replica(s)
S: c9a2731b7db540b7937b4bde854be8a0817258f0 127.0.0.1:6386
slots: (0 slots) slave
replicates 9b53bc798f30f0c3aad64ae787ef97bfb520ed62
M: 0113a3532640fe678bd652bac626e4fc2fc32916 127.0.0.1:6383
slots:10923-16383 (5461 slots) master
1 additional replica(s)
M: e19b36f039d4c56db0e48c9ffda0d00555a9576a 127.0.0.1:6382
slots:5461-10922 (5462 slots) master
1 additional replica(s)
S: 4010a79852155581fffc9e632398898619a5db90 127.0.0.1:6385
slots: (0 slots) slave
replicates 0113a3532640fe678bd652bac626e4fc2fc32916
S: f9a65ed5171b9a66e70b4a12474386c4f9b47e35 127.0.0.1:6384
slots: (0 slots) slave
replicates e19b36f039d4c56db0e48c9ffda0d00555a9576a
[OK] All nodes agree about slots configuration.
>>> Check for open slots...
>>> Check slots coverage...
[OK] All 16384 slots covered.
最后的输出报告说明:16384个槽全部被分配,集群创建成功。这里需要注意给redis-trib.rb的节点地址必须是不包含任何槽/数据的节点,否则会拒绝创建集群。
集群检查
集群创建好后,还可以通过./redis-trib.rb check来检查集群的完整性,只需在集群中的任意节点执行即可。
[root@vagrant redis-6382]# ./redis-trib.rb check 127.0.0.1:6381
>>> Performing Cluster Check (using node 127.0.0.1:6381)
M: 9b53bc798f30f0c3aad64ae787ef97bfb520ed62 127.0.0.1:6381
slots:0-5460 (5461 slots) master
1 additional replica(s)
S: c9a2731b7db540b7937b4bde854be8a0817258f0 127.0.0.1:6386
slots: (0 slots) slave
replicates 9b53bc798f30f0c3aad64ae787ef97bfb520ed62
M: 0113a3532640fe678bd652bac626e4fc2fc32916 127.0.0.1:6383
slots:10923-16383 (5461 slots) master
1 additional replica(s)
M: e19b36f039d4c56db0e48c9ffda0d00555a9576a 127.0.0.1:6382
slots:5461-10922 (5462 slots) master
1 additional replica(s)
S: 4010a79852155581fffc9e632398898619a5db90 127.0.0.1:6385
slots: (0 slots) slave
replicates 0113a3532640fe678bd652bac626e4fc2fc32916
S: f9a65ed5171b9a66e70b4a12474386c4f9b47e35 127.0.0.1:6384
slots: (0 slots) slave
replicates e19b36f039d4c56db0e48c9ffda0d00555a9576a
[OK] All nodes agree about slots configuration.
>>> Check for open slots...
>>> Check slots coverage...
[OK] All 16384 slots covered.
集群伸缩
原理
redis的集群伸缩是在不影响集群对外服务的前提下,对集群增加节点(扩容)与减少节点(收缩)。
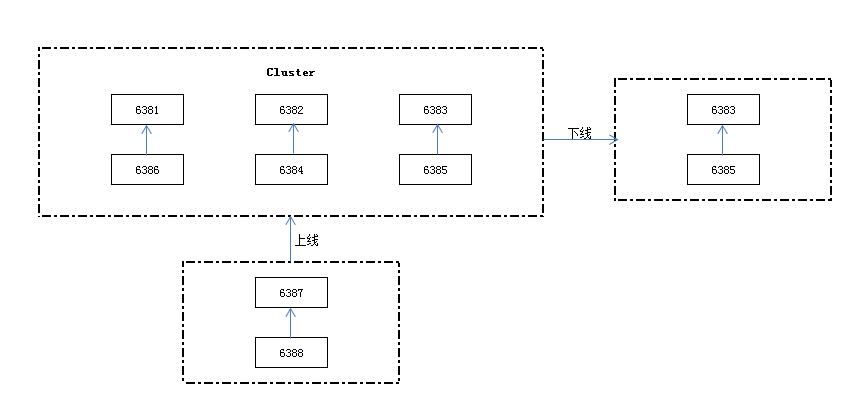
redis集群可以方便的进行节点上下线控制,原理是依赖于槽和数据在节点中的灵活移动。
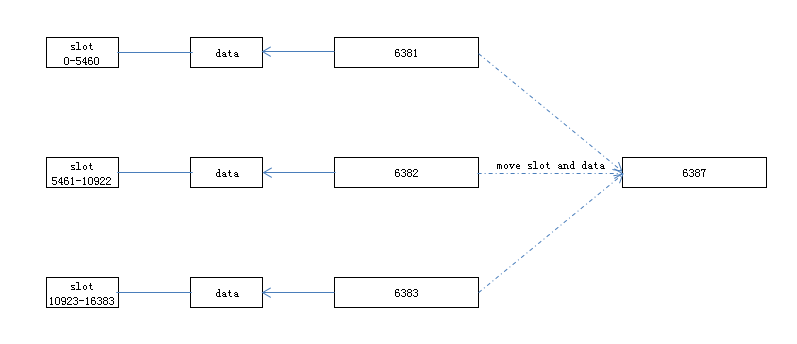
扩容
准备新节点
为了扩容集群首先需要准备节点,节点的配置最好与集群中其他节点一致,从机数量也可保持与集群中主节点的从机数一致。
[root@vagrant redis-6388]# ps -ef|grep redis
root 18625 1 0 14:02 ? 00:00:00 ./redis-server *:6387 [cluster]
root 18638 1 0 14:03 ? 00:00:00 ./redis-server *:6388 [cluster]
...
加入集群
可使用cluster meet命令,这里推荐使用redis-trib.rb add-node命令加入新节点,此命令可以帮助检查新节点是否属于其他集群或者已经包含数据。
[root@vagrant redis-6388]# ./redis-trib.rb add-node 127.0.0.1:6387 127.0.0.1:6381
#在加入节点时指定主节点
[root@vagrant redis-6388]# ./redis-trib.rb add-node --slave --master-id 96db27a74fd2717b9e65a7b843831de53158e273 127.0.0.1:6388 127.0.0.1:6381
添加好节点后,集群节点变为如下
[root@vagrant redis-6388]# ./redis-cli -p 6381 cluster nodes
c9a2731b7db540b7937b4bde854be8a0817258f0 127.0.0.1:6386@16386 slave 9b53bc798f30f0c3aad64ae787ef97bfb520ed62 0 1539758431000 6 connd
8dc6f1d391ea4ae1f2fbc1ced10f2af356c34c31 127.0.0.1:6388@16388 slave 96db27a74fd2717b9e65a7b843831de53158e273 0 1539758433949 7 connd
0113a3532640fe678bd652bac626e4fc2fc32916 127.0.0.1:6383@16383 master - 0 1539758433000 3 connected 10923-16383
e19b36f039d4c56db0e48c9ffda0d00555a9576a 127.0.0.1:6382@16382 master - 0 1539758431939 2 connected 5461-10922
4010a79852155581fffc9e632398898619a5db90 127.0.0.1:6385@16385 slave 0113a3532640fe678bd652bac626e4fc2fc32916 0 1539758431000 5 connd
9b53bc798f30f0c3aad64ae787ef97bfb520ed62 127.0.0.1:6381@16381 myself,master - 0 1539758431000 1 connected 0-5460
f9a65ed5171b9a66e70b4a12474386c4f9b47e35 127.0.0.1:6384@16384 slave e19b36f039d4c56db0e48c9ffda0d00555a9576a 0 1539758430000 4 connd
96db27a74fd2717b9e65a7b843831de53158e273 127.0.0.1:6387@16387 master - 0 1539758432000 0 connected
迁移槽和数据
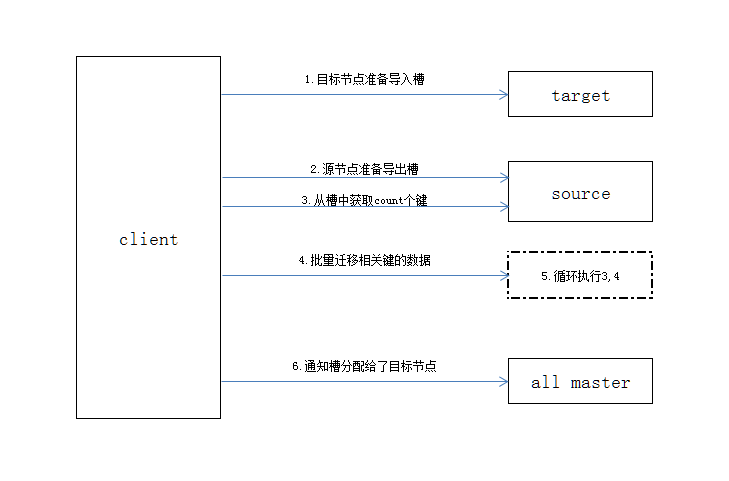
新的节点加入到集群后,需要将现有主节点上的槽迁移到新节点上,同时确保迁移后每个节点上的槽数是均衡的。根据以上规则得到每个节点有哪些槽需要被迁移,确定好计划后就开始逐个将数据从源节点转移到目标节点。数据转移流程:
- 对目标节点发送cluster setslot {slot} importing {sourceNodeId}命令,让目标节点准备导入槽的数据
- 对源节点发送cluster setslot {slot} migrating {targetNodeId}命令,让源节点准备迁出槽的数据
- 源节点循环执行cluster getkeysinslot {slot} {count}命令,获取count个属于槽{slot}的键
- 在源节点上执行migrate {targetIp} {targetPort} “” 0 {timeout} keys {keys…}命令,把获取的键通过流水线(pipeline)机制批量迁移到目标节点
- 重复执行步骤(3,4)直到槽下所有的键值数据迁移到目标节点
- 向集群内所有主节点发送cluster setslot {slot} node {targetNodeId}命令,通知槽分配给目标节点。为了保证槽节点映射变更及时传播,需要遍历发送给所有主节点更新被迁移的槽指向新节点
手动执行命令将槽1180从6381节点迁移到6387节点。
#1.节点6387准备导入槽1180数据
[root@vagrant redis-6388]# ./redis-cli -p 6387 cluster setslot 1180 importing 9b53bc798f30f0c3aad64ae787ef97bfb520ed62
OK
#6387槽1180导入状态开启
#如果需要可通过"cluster setslot 1180 stable"取消槽迁移
[root@vagrant redis-6388]# ./redis-cli -p 6387 cluster nodes
96db27a74fd2717b9e65a7b843831de53158e273 127.0.0.1:6387@16387 myself,master - 0 1539765189000 0 connected [1180-<-9b53bc798f30f0c3aad64ae787ef97bfb520ed62]
#2.节点6381准备导出槽1180数据
[root@vagrant redis-6388]# ./redis-cli -p 6381 cluster setslot 1180 migrating 96db27a74fd2717b9e65a7b843831de53158e273
OK
#6381槽1180导出状态开启
[root@vagrant redis-6388]# ./redis-cli -p 6381 cluster nodes
9b53bc798f30f0c3aad64ae787ef97bfb520ed62 127.0.0.1:6381@16381 myself,master - 0 1539766397000 1 connected 0-5460 [1180->-96db27a74fd2717b9e65a7b843831de53158e273]
#3.批量获取槽1180的键
[root@vagrant redis-6388]# ./redis-cli -p 6381 cluster getkeysinslot 1180 100
1) "aa"
#4.批量转移键
[root@vagrant redis-6388]# ./redis-cli -p 6381 migrate 127.0.0.1 6387 "" 0 5000 keys aa
OK
#键已经不在源节点了,回复"ASK"引导客户端找到真实数据节点
[root@vagrant redis-6388]# ./redis-cli -p 6381 get aa
(error) ASK 1180 127.0.0.1:6387
#5.通知所有主节点槽1180已经被分配给节点6387
[root@vagrant redis-6388]# ./redis-cli -p 6381 cluster setslot 1180 node 96db27a74fd2717b9e65a7b843831de53158e273
OK
[root@vagrant redis-6388]# ./redis-cli -p 6382 cluster setslot 1180 node 96db27a74fd2717b9e65a7b843831de53158e273
OK
[root@vagrant redis-6388]# ./redis-cli -p 6383 cluster setslot 1180 node 96db27a74fd2717b9e65a7b843831de53158e273
OK
[root@vagrant redis-6388]# ./redis-cli -p 6387 cluster setslot 1180 node 96db27a74fd2717b9e65a7b843831de53158e273
OK
#6.槽与数据迁移完成
[root@vagrant redis-6388]# ./redis-cli -p 6381 cluster nodes
c9a2731b7db540b7937b4bde854be8a0817258f0 127.0.0.1:6386@16386 slave 9b53bc798f30f0c3aad64ae787ef97bfb520ed62 0 1539767465226 6 connected
8dc6f1d391ea4ae1f2fbc1ced10f2af356c34c31 127.0.0.1:6388@16388 slave 96db27a74fd2717b9e65a7b843831de53158e273 0 1539767466233 8 connected
0113a3532640fe678bd652bac626e4fc2fc32916 127.0.0.1:6383@16383 master - 0 1539767464222 3 connected 10923-16383
e19b36f039d4c56db0e48c9ffda0d00555a9576a 127.0.0.1:6382@16382 master - 0 1539767467240 2 connected 5461-10922
4010a79852155581fffc9e632398898619a5db90 127.0.0.1:6385@16385 slave 0113a3532640fe678bd652bac626e4fc2fc32916 0 1539767468243 5 connected
9b53bc798f30f0c3aad64ae787ef97bfb520ed62 127.0.0.1:6381@16381 myself,master - 0 1539767466000 1 connected 0-1179 1181-5460
f9a65ed5171b9a66e70b4a12474386c4f9b47e35 127.0.0.1:6384@16384 slave e19b36f039d4c56db0e48c9ffda0d00555a9576a 0 1539767467000 4 connected
96db27a74fd2717b9e65a7b843831de53158e273 127.0.0.1:6387@16387 master - 0 1539767466000 8 connected 1180
对于线上环境的redis集群,由于迁移槽与数据量都会比较大,最好还是使用redis-trib.rb reshard命令。
#命令说明
#host:port:必传参数,集群内任意节点地址,用来获取整个集群信息
#--from:制定源节点的id,如果有多个源节点,使用逗号分隔,如果是all源节点变为集群内所有主节点,在迁移过程中提示用户输入
#--to:需要迁移的目标节点的id,目标节点只能填写一个,在迁移过程中提示用户输入
#--slots:需要迁移槽的总数量,在迁移过程中提示用户输入
#--yes:当打印出reshard执行计划时,是否需要用户输入yes确认后再执行reshard
#--timeout:控制每次migrate操作的超时时间,默认为60000毫秒
#--pipeline:控制每次批量迁移键的数量,默认为10
redis-trib.rb reshard host:port --from <arg> --to <arg> --slots <arg> --yes --timeout <arg> --pipeline <arg>
使用redis-trib.rb来迁移剩余的slot
#1.开启迁移,显示集群信息,提示输入迁移槽个数
[root@vagrant redis-6388]# ./redis-trib.rb reshard 127.0.0.1:6381
>>> Performing Cluster Check (using node 127.0.0.1:6381)
M: 9b53bc798f30f0c3aad64ae787ef97bfb520ed62 127.0.0.1:6381
slots:0-1179,1181-5460 (5460 slots) master
1 additional replica(s)
...
[OK] All nodes agree about slots configuration.
>>> Check for open slots...
>>> Check slots coverage...
[OK] All 16384 slots covered.
How many slots do you want to move (from 1 to 16384)?
#2.输入4096,提示输入目标id
How many slots do you want to move (from 1 to 16384)? 4096
What is the receiving node ID?
#3.输入目标id,提示输入源id
What is the receiving node ID? 96db27a74fd2717b9e65a7b843831de53158e273
Please enter all the source node IDs.
Type 'all' to use all the nodes as source nodes for the hash slots.
Type 'done' once you entered all the source nodes IDs.
Source node #1:
#4.输入3个源id,显示迁移计划,提示输入yes
...
Moving slot 1361 from 9b53bc798f30f0c3aad64ae787ef97bfb520ed62
Moving slot 1362 from 9b53bc798f30f0c3aad64ae787ef97bfb520ed62
Moving slot 1363 from 9b53bc798f30f0c3aad64ae787ef97bfb520ed62
...
Do you want to proceed with the proposed reshard plan (yes/no)?
#5.输入yes开始迁移,显示迁移状态
...
Moving slot 1338 from 127.0.0.1:6381 to 127.0.0.1:6387:
Moving slot 1339 from 127.0.0.1:6381 to 127.0.0.1:6387:
Moving slot 1340 from 127.0.0.1:6381 to 127.0.0.1:6387:
Moving slot 1341 from 127.0.0.1:6381 to 127.0.0.1:6387:
...
#6.迁移结束查看节点状态
[root@vagrant redis-6388]# ./redis-cli -p 6381 cluster nodes
c9a2731b7db540b7937b4bde854be8a0817258f0 127.0.0.1:6386@16386 slave 9b53bc798f30f0c3aad64ae787ef97bfb520ed62 0 1539768765984 6 connected
8dc6f1d391ea4ae1f2fbc1ced10f2af356c34c31 127.0.0.1:6388@16388 slave 96db27a74fd2717b9e65a7b843831de53158e273 0 1539768763000 8 connected
0113a3532640fe678bd652bac626e4fc2fc32916 127.0.0.1:6383@16383 master - 0 1539768762000 3 connected 12288-16383
e19b36f039d4c56db0e48c9ffda0d00555a9576a 127.0.0.1:6382@16382 master - 0 1539768762972 2 connected 6827-10922
4010a79852155581fffc9e632398898619a5db90 127.0.0.1:6385@16385 slave 0113a3532640fe678bd652bac626e4fc2fc32916 0 1539768764981 5 connected
9b53bc798f30f0c3aad64ae787ef97bfb520ed62 127.0.0.1:6381@16381 myself,master - 0 1539768764000 1 connected 1366-5460
f9a65ed5171b9a66e70b4a12474386c4f9b47e35 127.0.0.1:6384@16384 slave e19b36f039d4c56db0e48c9ffda0d00555a9576a 0 1539768763000 4 connected
96db27a74fd2717b9e65a7b843831de53158e273 127.0.0.1:6387@16387 master - 0 1539768763977 8 connected 0-1365 5461-6826 10923-12287
#7.查看集群的平衡性
[root@vagrant redis-6388]# ./redis-trib.rb rebalance 127.0.0.1:6381
>>> Performing Cluster Check (using node 127.0.0.1:6381)
[OK] All nodes agree about slots configuration.
>>> Check for open slots...
>>> Check slots coverage...
[OK] All 16384 slots covered.
*** No rebalancing needed! All nodes are within the 2.0% threshold.
收缩
由于业务或硬件更换可能需要从集群下线节点,一般流程如下:
- 首先需要确定下线节点是否有负责的槽,如果有,需要把槽迁移到其他节点,保证节点下线后整个集群槽节点映射的完整性
- 当下线节点不再负责槽或者本身是从节点时,就可以通知集群内其他节点忘记下线节点,当所有的节点忘记该节点后可以正常关闭
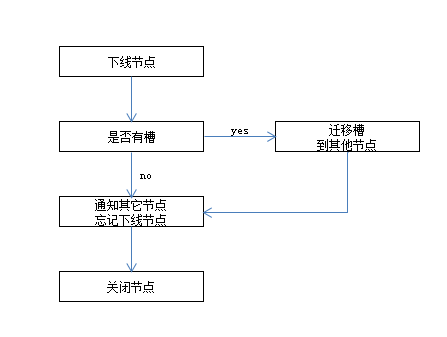
下线迁移槽
下线节点需要迁移槽,原理与扩容迁移槽的过程一致,这里下线6383(master)与6385(slave),需要把主节点6383上的槽均匀迁移到另外3个主节点上。
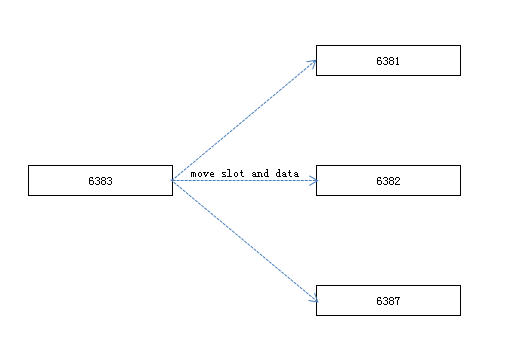
每次执行redis-trib.rb reshard只能有一个目标节点,所以需要执行3此reshard命令。
#第一次迁移1365个槽->6381
[root@vagrant redis-6388]# ./redis-trib.rb reshard 127.0.0.1:6381
>>> Performing Cluster Check (using node 127.0.0.1:6381)
...
[OK] All nodes agree about slots configuration.
>>> Check for open slots...
>>> Check slots coverage...
[OK] All 16384 slots covered.
How many slots do you want to move (from 1 to 16384)? 1365
What is the receiving node ID? 9b53bc798f30f0c3aad64ae787ef97bfb520ed62
Please enter all the source node IDs.
Type 'all' to use all the nodes as source nodes for the hash slots.
Type 'done' once you entered all the source nodes IDs.
Source node #1:0113a3532640fe678bd652bac626e4fc2fc32916
Source node #2:done
#第二次迁移1365个槽->6382
[root@vagrant redis-6388]# ./redis-trib.rb reshard 127.0.0.1:6381
>>> Performing Cluster Check (using node 127.0.0.1:6381)
...
[OK] All nodes agree about slots configuration.
>>> Check for open slots...
>>> Check slots coverage...
[OK] All 16384 slots covered.
How many slots do you want to move (from 1 to 16384)? 1365
What is the receiving node ID? e19b36f039d4c56db0e48c9ffda0d00555a9576a
Please enter all the source node IDs.
Type 'all' to use all the nodes as source nodes for the hash slots.
Type 'done' once you entered all the source nodes IDs.
Source node #1:0113a3532640fe678bd652bac626e4fc2fc32916
Source node #2:done
#第一次迁移1366个槽->6387
[root@vagrant redis-6388]# ./redis-trib.rb reshard 127.0.0.1:6381
>>> Performing Cluster Check (using node 127.0.0.1:6381)
...
[OK] All nodes agree about slots configuration.
>>> Check for open slots...
>>> Check slots coverage...
[OK] All 16384 slots covered.
How many slots do you want to move (from 1 to 16384)? 1365
What is the receiving node ID? 96db27a74fd2717b9e65a7b843831de53158e273
Please enter all the source node IDs.
Type 'all' to use all the nodes as source nodes for the hash slots.
Type 'done' once you entered all the source nodes IDs.
Source node #1:0113a3532640fe678bd652bac626e4fc2fc32916
Source node #2:done
全部迁移完成后查看集群节点状态,确保迁移结果是正确的
#集群状态
[root@vagrant redis-6388]# ./redis-cli -p 6381 cluster nodes
c9a2731b7db540b7937b4bde854be8a0817258f0 127.0.0.1:6386@16386 slave 9b53bc798f30f0c3aad64ae787ef97bfb520ed62 0 1539831140899 9 connected
8dc6f1d391ea4ae1f2fbc1ced10f2af356c34c31 127.0.0.1:6388@16388 slave 96db27a74fd2717b9e65a7b843831de53158e273 0 1539831137000 8 connected
0113a3532640fe678bd652bac626e4fc2fc32916 127.0.0.1:6383@16383 master - 0 1539831140000 3 connected
e19b36f039d4c56db0e48c9ffda0d00555a9576a 127.0.0.1:6382@16382 master - 0 1539831137000 10 connected 6827-10922 13653-15017
4010a79852155581fffc9e632398898619a5db90 127.0.0.1:6385@16385 slave 0113a3532640fe678bd652bac626e4fc2fc32916 0 1539831139000 5 connected
9b53bc798f30f0c3aad64ae787ef97bfb520ed62 127.0.0.1:6381@16381 myself,master - 0 1539831138000 9 connected 1366-5460 12288-13652
f9a65ed5171b9a66e70b4a12474386c4f9b47e35 127.0.0.1:6384@16384 slave e19b36f039d4c56db0e48c9ffda0d00555a9576a 0 1539831139895 10 connected
96db27a74fd2717b9e65a7b843831de53158e273 127.0.0.1:6387@16387 master - 0 1539831137884 11 connected 0-1365 5461-6826 10923-12287 15018-16383
#检查集群
[root@vagrant redis-6388]# ./redis-trib.rb check 127.0.0.1:6381
>>> Performing Cluster Check (using node 127.0.0.1:6381)
M: 9b53bc798f30f0c3aad64ae787ef97bfb520ed62 127.0.0.1:6381
slots:1366-5460,12288-13652 (5460 slots) master
1 additional replica(s)
S: c9a2731b7db540b7937b4bde854be8a0817258f0 127.0.0.1:6386
slots: (0 slots) slave
replicates 9b53bc798f30f0c3aad64ae787ef97bfb520ed62
S: 8dc6f1d391ea4ae1f2fbc1ced10f2af356c34c31 127.0.0.1:6388
slots: (0 slots) slave
replicates 96db27a74fd2717b9e65a7b843831de53158e273
M: 0113a3532640fe678bd652bac626e4fc2fc32916 127.0.0.1:6383
slots: (0 slots) master
0 additional replica(s)
M: e19b36f039d4c56db0e48c9ffda0d00555a9576a 127.0.0.1:6382
slots:6827-10922,13653-15017 (5461 slots) master
1 additional replica(s)
S: 4010a79852155581fffc9e632398898619a5db90 127.0.0.1:6385
slots: (0 slots) slave
replicates 96db27a74fd2717b9e65a7b843831de53158e273
S: f9a65ed5171b9a66e70b4a12474386c4f9b47e35 127.0.0.1:6384
slots: (0 slots) slave
replicates e19b36f039d4c56db0e48c9ffda0d00555a9576a
M: 96db27a74fd2717b9e65a7b843831de53158e273 127.0.0.1:6387
slots:0-1365,5461-6826,10923-12287,15018-16383 (5463 slots) master
2 additional replica(s)
[OK] All nodes agree about slots configuration.
>>> Check for open slots...
>>> Check slots coverage...
[OK] All 16384 slots covered.
忘记节点
redis提供了cluster forget {downNodeId}来将被忘记节点加入到禁用列表中,不过需要在60s内在所有节点上执行此命令,否则节点会恢复通信,此种方式不适合在线上环境使用。
这里使用redis-trib.rb del-node来忘记节点,为了避免从节点的全量复制,优先下线从节点,再下线主节点。
[root@vagrant redis-6388]# ./redis-trib.rb del-node 127.0.0.1:6381 4010a79852155581fffc9e632398898619a5db90
>>> Removing node 4010a79852155581fffc9e632398898619a5db90 from cluster 127.0.0.1:6381
>>> Sending CLUSTER FORGET messages to the cluster...
>>> SHUTDOWN the node.
[root@vagrant redis-6388]# ./redis-trib.rb del-node 127.0.0.1:6381 0113a3532640fe678bd652bac626e4fc2fc32916
>>> Removing node 0113a3532640fe678bd652bac626e4fc2fc32916 from cluster 127.0.0.1:6381
>>> Sending CLUSTER FORGET messages to the cluster...
>>> SHUTDOWN the node.
查看集群节点与redis进程信息,确认节点已下线
#集群信息
[root@vagrant redis-6388]# ./redis-cli -p 6381 cluster nodes
c9a2731b7db540b7937b4bde854be8a0817258f0 127.0.0.1:6386@16386 slave 9b53bc798f30f0c3aad64ae787ef97bfb520ed62 0 1539840155493 9 connected
8dc6f1d391ea4ae1f2fbc1ced10f2af356c34c31 127.0.0.1:6388@16388 slave 96db27a74fd2717b9e65a7b843831de53158e273 0 1539840154000 11 connected
e19b36f039d4c56db0e48c9ffda0d00555a9576a 127.0.0.1:6382@16382 master - 0 1539840155000 10 connected 6827-10922 13653-15017
9b53bc798f30f0c3aad64ae787ef97bfb520ed62 127.0.0.1:6381@16381 myself,master - 0 1539840154000 9 connected 1366-5460 12288-13652
f9a65ed5171b9a66e70b4a12474386c4f9b47e35 127.0.0.1:6384@16384 slave e19b36f039d4c56db0e48c9ffda0d00555a9576a 0 1539840156497 10 connected
96db27a74fd2717b9e65a7b843831de53158e273 127.0.0.1:6387@16387 master - 0 1539840154000 11 connected 0-1365 5461-6826 10923-12287 15018-16383
#redis进程
[root@vagrant redis-6388]# ps -ef|grep redis
root 18040 1 0 Oct16 ? 00:03:40 ./redis-server *:6381 [cluster]
root 18054 1 0 Oct16 ? 00:03:35 ./redis-server *:6384 [cluster]
root 18064 1 0 Oct16 ? 00:03:34 ./redis-server *:6386 [cluster]
root 18071 1 0 Oct16 ? 00:03:40 ./redis-server *:6382 [cluster]
root 18625 1 0 Oct17 ? 00:02:02 ./redis-server *:6387 [cluster]
root 18855 1 0 Oct17 ? 00:01:53 ./redis-server *:6388 [cluster]
Tips:对于已下线的节点,如果需要重新启动的话,最好删除掉持久化文件(aof或rdb)与集群配置文件(nodes-{port}.conf),否则在启动时会加载
故障转移
redis自身实现了故障转移,不需要依赖sentinel来进行故障转移。
故障发现
主观下线
当cluster-note-timeout时间内某节点无法与另一个节点顺利完成ping消息通信时,则将该节点标记为主观下线状态。
客观下线
当集群中半数以上持有槽的主节点都标记某个节点是主观下线时,触发客观下线流程。向集群广播一条fail消息,通知所有的节点将故障节点标记为客观下线。
Tips:如果在cluster-node-time*2时间内无法收集到一半以上槽节点的下线报告,那么之前的下线报告将会过期,因此不能将cluster-node-time设置得过小。
故障恢复
故障节点变为客观下线后,如果下线节点是持有槽的主节点则需要在它的从节点中选出一个替换它,从而保证集群的高可用。主要流程:
- 资格检查
- 准备选举时间
- 发起选举
- 选举投票
- 替换主节点
资格检查
获取有资格进行故障替换的从节点,主从断线时间<=cluster-node-timeout*cluster-slave-alidity-factor(默认为10)
准备选举时间
从节点根据自身复制偏移量设置延迟选举时间,如复制偏移量最大的节点slave b-1延迟1秒执行,保证复制延迟低的从节点优先发起选举
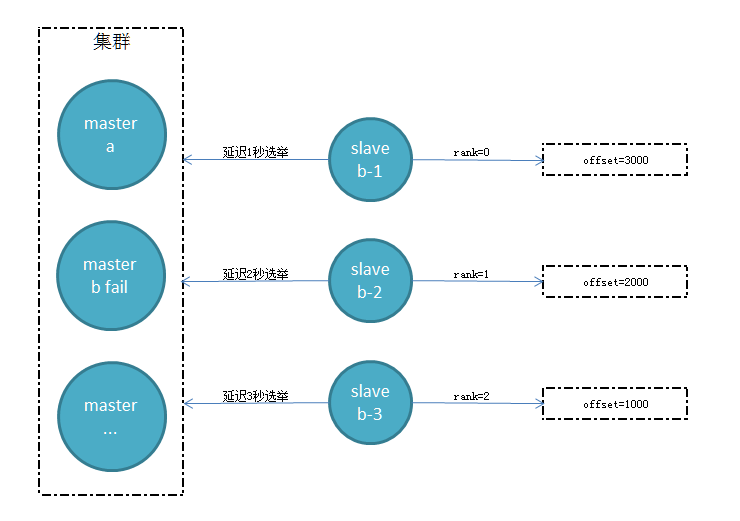
发起选举
当从节点判断到达故障选举时间后,在集群内广播选举消息(FAILOVER_AUTH_REQUEST),并记录已发送过消息的状态,保证该从节点在一个配置纪元内只能发起一次选举。
选举投票
只有拥有槽的主节点才能对选举进行投票,且在一个配置纪元内只能投票一次,当从节点收集到N(所有槽主节点)/2+1个持有槽主节点投票时,从节点即可执行替换主节点操作。
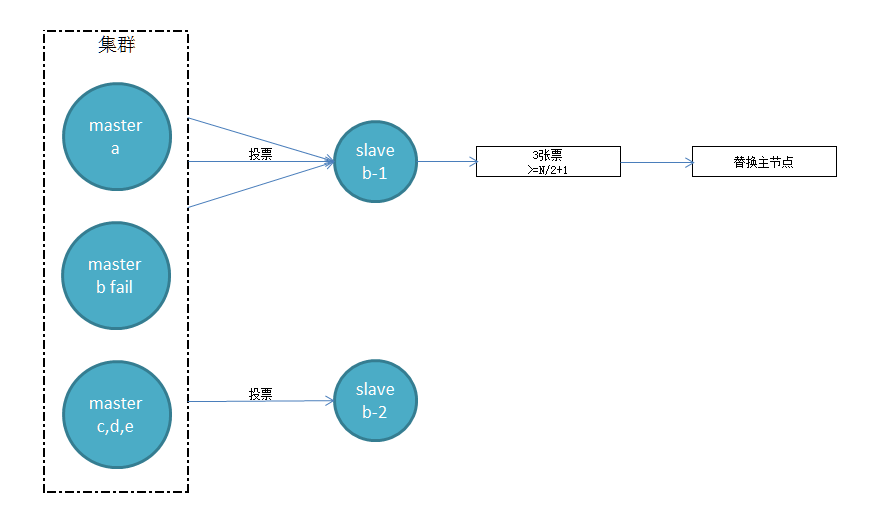
Tips:因为故障的主节点也在投票数内,如果在一台物理机上部署多个主节点时,当物理机出现故障可能会导致故障转移失败,所以部署集群时主节点最好部署在多台物理机上。
替换主节点
当确定由哪个主节点替换主节点后,即可进行一下操作:
- 当前从节点取消复制变为主节点
- 执行clusterDelSlot操作撤销故障主节点负责的槽,并执行clusterAddSlot把这些槽委派给自己
- 向集群广播自己的pong消息,通知集群内所有的节点当前从节点变为主节点并接管了故障主节点的槽信息
故障转移时间
通过上面的流程可以得知故障转移需要花费的时间(failover_time)<=cluster-node-timeout +cluster-node-timeout/2 + 1000
- 主观下线(pfail)识别时间=cluster-node-timeout
- 主观下线状态消息传播时间<=cluster-node-timeout/2
- 从节点转移时间<=1000毫秒
因此故障转移时间跟cluster-node-timeout参数息息相关(默认15秒),配置时可以根据业务容忍度做出适当调整。
故障转移测试
下面对现有集群模拟故障转移
#初始集群信息
[root@vagrant redis-6388]# ./redis-cli -p 6381 cluster nodes
c9a2731b7db540b7937b4bde854be8a0817258f0 127.0.0.1:6386@16386 slave 9b53bc798f30f0c3aad64ae787ef97bfb520ed62 0 1539853344532 9 connected
8dc6f1d391ea4ae1f2fbc1ced10f2af356c34c31 127.0.0.1:6388@16388 slave 96db27a74fd2717b9e65a7b843831de53158e273 0 1539853346544 11 connected
e19b36f039d4c56db0e48c9ffda0d00555a9576a 127.0.0.1:6382@16382 master - 0 1539853346000 10 connected 6827-10922 13653-15017
9b53bc798f30f0c3aad64ae787ef97bfb520ed62 127.0.0.1:6381@16381 myself,master - 0 1539853345000 9 connected 1366-5460 12288-13652
f9a65ed5171b9a66e70b4a12474386c4f9b47e35 127.0.0.1:6384@16384 slave e19b36f039d4c56db0e48c9ffda0d00555a9576a 0 1539853345539 10 connected
96db27a74fd2717b9e65a7b843831de53158e273 127.0.0.1:6387@16387 master - 0 1539853347551 11 connected 0-1365 5461-6826 10923-12287 15018-16383
使用kill -9 {pid}强制关闭6387主节点。
#查看最新集群信息,故障已转移,6388变为新主节点
[root@vagrant redis-6388]# ./redis-cli -p 6381 cluster nodes
c9a2731b7db540b7937b4bde854be8a0817258f0 127.0.0.1:6386@16386 slave 9b53bc798f30f0c3aad64ae787ef97bfb520ed62 0 1539853959000 9 connected
8dc6f1d391ea4ae1f2fbc1ced10f2af356c34c31 127.0.0.1:6388@16388 master - 0 1539853958000 12 connected 0-1365 5461-6826 10923-12287 15018-16383
e19b36f039d4c56db0e48c9ffda0d00555a9576a 127.0.0.1:6382@16382 master - 0 1539853959841 10 connected 6827-10922 13653-15017
9b53bc798f30f0c3aad64ae787ef97bfb520ed62 127.0.0.1:6381@16381 myself,master - 0 1539853960000 9 connected 1366-5460 12288-13652
f9a65ed5171b9a66e70b4a12474386c4f9b47e35 127.0.0.1:6384@16384 slave e19b36f039d4c56db0e48c9ffda0d00555a9576a 0 1539853960853 10 connected
96db27a74fd2717b9e65a7b843831de53158e273 127.0.0.1:6387@16387 master,fail - 1539853943825 1539853941716 11 disconnected
重启6387节点,启动后发现自己负责的槽已被指派给另一个节点,则以现有集群配置为准,变为新主节点6388的从节点。
[root@vagrant redis-6387]# ./redis-server redis.conf
[root@vagrant redis-6387]# ./redis-cli -p 6381 cluster nodes
c9a2731b7db540b7937b4bde854be8a0817258f0 127.0.0.1:6386@16386 slave 9b53bc798f30f0c3aad64ae787ef97bfb520ed62 0 1539854292000 9 connected
8dc6f1d391ea4ae1f2fbc1ced10f2af356c34c31 127.0.0.1:6388@16388 master - 0 1539854294121 12 connected 0-1365 5461-6826 10923-12287 15018-16383
e19b36f039d4c56db0e48c9ffda0d00555a9576a 127.0.0.1:6382@16382 master - 0 1539854293116 10 connected 6827-10922 13653-15017
9b53bc798f30f0c3aad64ae787ef97bfb520ed62 127.0.0.1:6381@16381 myself,master - 0 1539854291000 9 connected 1366-5460 12288-13652
f9a65ed5171b9a66e70b4a12474386c4f9b47e35 127.0.0.1:6384@16384 slave e19b36f039d4c56db0e48c9ffda0d00555a9576a 0 1539854292000 10 connected
96db27a74fd2717b9e65a7b843831de53158e273 127.0.0.1:6387@16387 slave 8dc6f1d391ea4ae1f2fbc1ced10f2af356c34c31 0 1539854292113 12 connected
集群运维
集群完整性
默认情况下当集群16384个槽任何一个没有指派到节点时整个集群不可用。执行任何键命令返回(error)CLUSTERDOWNHash slot not served错误。建议将参数cluster-require-full-coverage配置为no,当主节点故障只影响它负责槽的相关命令执行,不会影响其他主节点的可用性。
[root@vagrant redis-6381]# ./redis-cli -p 6381 config get cluster-require-full-coverage
1) "cluster-require-full-coverage"
2) "yes"
读写分离
集群模式下从节点是不能处理读写请求的,发送过来的命令会重定向到相应槽的主节点上。如果需要从节点可以处理读的请求,需要使用readyonly命令来设置客户端的只读状态。
[root@vagrant redis-6381]# ./redis-cli -p 6384
127.0.0.1:6384> get b
(error) MOVED 3300 127.0.0.1:6381
127.0.0.1:6384> readonly
OK
127.0.0.1:6384> get b
(nil)
Tips:readonly命令是连接级别生效,因此每次新建连接时都需要执行readonly开启只读状态。执行readwrite命令可以关闭连接只读状态。
手动故障转移
当需要对主节点迁移或自动故障转移失败时,可手动进行故障转移。在需要故障转移的主节点对应的从节点里,选取一个可变为主节点的从节点执行cluster failover命令,此从节点就会变为新主节点。
#6386为6383的从节点
[root@vagrant redis-6381]# ./redis-cli -p 6381 cluster nodes
8613c01624d779fe892002ef48e2ea3ebcdc4c6b 127.0.0.1:6386@16386 slave 7d024eba97453219dda1375cfbf2bf9105841299 0 1539934116000 6 connected
7d024eba97453219dda1375cfbf2bf9105841299 127.0.0.1:6383@16383 master - 0 1539934117445 3 connected 10923-16383
#在6386上执行故障转移
[root@vagrant redis-6381]# ./redis-cli -p 6386 cluster failover
OK
#6383变为6386的从节点
[root@vagrant redis-6381]# ./redis-cli -p 6381 cluster nodes
8613c01624d779fe892002ef48e2ea3ebcdc4c6b 127.0.0.1:6386@16386 master - 0 1539934245070 7 connected 10923-16383
7d024eba97453219dda1375cfbf2bf9105841299 127.0.0.1:6383@16383 slave 8613c01624d779fe892002ef48e2ea3ebcdc4c6b 0 1539934249094 7 connected
默认情况下转移期间客户端请求会有短暂的阻塞,但不会丢失数据,流程如下:
- 从节点通知主节点停止处理所有客户端请求
- 主节点发送对应从节点延迟复制的数据
- 从节点接收处理复制延迟的数据,直到主从复制偏移量一致为止,保证复制数据不丢失
- 从节点立刻发起投票选举(这里不需要延迟触发选举)。选举成功后断开复制变为新的主节点,之后向集群广播主节点pong消息,故障转移细节见10.6故障恢复部分
- 旧主节点接受到消息后更新自身配置变为从节点,解除所有客户端请求阻塞,这些请求会被重定向到新主节点上执行
- 旧主节点变为从节点后,向新的主节点发起全量复制流程
数据迁移
当准备使用redis集群时,一般都需要把数据从单机迁移到集群环境,推荐使用唯品会开源的redis-migrate-tool。
下面尝试使用此工具,进行一次redis单机到集群的数据迁移。
1.环境准备
准备redis单机环境,6387(master),6388(slave)
[root@vagrant redis-6388]# ps -ef|grep redis
root 12689 1 0 10:33 ? 00:00:00 ./redis-server *:6387
root 12694 1 0 10:33 ? 00:00:00 ./redis-server *:6388
[root@vagrant redis-6388]# ./redis-cli -p 6387 info replication
# Replication
role:master
connected_slaves:1
slave0:ip=127.0.0.1,port=6388,state=online,offset=14,lag=1
...
准备redis集群环境
[root@vagrant redis-6386]# ps -ef|grep redis
root 12709 1 0 10:52 ? 00:00:00 ./redis-server *:6381 [cluster]
root 12714 1 0 10:52 ? 00:00:00 ./redis-server *:6382 [cluster]
root 12719 1 0 10:52 ? 00:00:00 ./redis-server *:6383 [cluster]
root 12724 1 0 10:52 ? 00:00:00 ./redis-server *:6384 [cluster]
root 12729 1 0 10:52 ? 00:00:00 ./redis-server *:6385 [cluster]
root 12734 1 0 10:53 ? 00:00:00 ./redis-server *:6386 [cluster]
[root@vagrant redis-6386]# ./redis-cli -p 6381 cluster nodes
1b1025d40c5e4d46941996ca382a2a07069dadb8 127.0.0.1:6382@16382 master - 0 1539919113086 2 connected 5461-10922
3561068ac19a730fe98fb9e90fc85c7487319d17 127.0.0.1:6385@16385 slave 1b1025d40c5e4d46941996ca382a2a07069dadb8 0 1539919114089 5 connected
dbc68e4e6ad2fccbe4383899a9e9f8156bfe8caa 127.0.0.1:6384@16384 slave 17bd7b9527f6ec1bb55976925ce7813d7acde6e0 0 1539919112081 4 connected
8613c01624d779fe892002ef48e2ea3ebcdc4c6b 127.0.0.1:6386@16386 slave 7d024eba97453219dda1375cfbf2bf9105841299 0 1539919111076 6 connected
7d024eba97453219dda1375cfbf2bf9105841299 127.0.0.1:6383@16383 master - 0 1539919111000 3 connected 10923-16383
17bd7b9527f6ec1bb55976925ce7813d7acde6e0 127.0.0.1:6381@16381 myself,master - 0 1539919112000 1 connected 0-5460
准备redis单机数据,确保测试数据在集群内分别属于不同的节点,用于之后检查数据迁移的准确性
#槽15495,节点6383
[root@vagrant redis-6386]# ./redis-cli -p 6387 set a 100
OK
#槽3300,节点6381
[root@vagrant redis-6386]# ./redis-cli -p 6387 set b 200
OK
#槽7365,节点6382
[root@vagrant redis-6386]# ./redis-cli -p 6387 set c 300
OK
2.工具安装
#安装依赖库
[root@vagrant redis-migrate-tool-master]# yum install libtool
#安装redis-migrate-tool
[root@vagrant bmsource]# wget https://github.com/vipshop/redis-migrate-tool/archive/master.zip -O redis-migrate-tool.zip
[root@vagrant bmsource]# unzip redis-migrate-tool.zip
[root@vagrant bmsource]# cd redis-migrate-tool-master/
[root@vagrant redis-migrate-tool-master]# autoreconf -fvi
[root@vagrant redis-migrate-tool-master]# ./configure
[root@vagrant redis-migrate-tool-master]# make
#查看工具帮助信息
[root@vagrant redis-migrate-tool-master]# src/redis-migrate-tool -h
This is redis-migrate-tool-0.1.0
Usage: redis-migrate-tool [-?hVdIn] [-v verbosity level] [-o output file]
[-c conf file] [-C command]
[-f source address] [-t target address]
[-p pid file] [-m mbuf size] [-r target role]
[-T thread number] [-b buffer size]
...
3.迁移数据
迁移配置文件rmt.conf
[source]
type: single
servers :
-127.0.0.1:6387
[target]
type: redis cluster
servers:
-127.0.0.1:6381
[common]
listen: 0.0.0.0:8888
执行命令迁移数据
[root@vagrant redis-migrate-tool-master]# src/redis-migrate-tool -c rmt.conf -o rmt.log -d
查看rmt.log文件,发现存在以下报错,查看仓库问题,此工具还不支持redis4.x版本
...
[2018-10-19 14:53:51.678] rmt_redis.c:1643 rdb file node127.0.0.1:6387-1539932031654768-21118.rdb write complete
[2018-10-19 14:53:51.678] rmt_redis.c:6446 ERROR: Can't handle RDB format version -782133880
[2018-10-19 14:53:51.678] rmt_redis.c:6715 ERROR: Rdb file for node[127.0.0.1:6387] parsed failed
...