介绍使用redis哨兵进行自动故障转移
前言
为了增强缓存服务器的高可用可使用redis的哨兵监控,来实现主节点发生故障时的自动转移。
准备工作
由于机器的限制,此文章中的redis实例都是在一台机器上启动的,通过不同的port来模拟不同的redis实例。
[root@vagrant redis-6383]# ps -ef|grep redis
root 4104 1 0 13:14 ? 00:00:00 ./redis-server *:6380
root 4113 1 0 13:18 ? 00:00:00 ./redis-server *:6381
root 4121 1 0 13:19 ? 00:00:00 ./redis-server *:6382
root 4129 1 0 13:19 ? 00:00:00 ./redis-server *:6383
配置文件
哨兵节点对应的配置文件为sentinel.conf,有如下一些配置项
| 名称 | 说明 | 可选值 |
| bind | 允许访问节点的ip protected-mode=yes时设置 |
自定义 |
| protected-mode | 保护模式 设置为no,确保网络在内网环境 |
yes|no |
| port | 端口 | 整数 |
| daemonize | 守护进程 | yes|no |
| pidfile | 进程文件 | 自定义 |
| logfile | 日志文件 | 自定义 |
| sentinel announce-ip | 对外宣称ip或port | 自定义 |
| sentinel announce-port | ||
| dir | 工作目录 | 自定义 |
| sentinel monitor <master-name> <ip> <redis-port> <quorum> |
监控的主节点 quorum: 1.至少有quorum个哨兵节点认为不可达,才会故障转移 2.至少有max(quorum,num(哨兵个数)/2+1)个哨兵节点参与选举才能进行故障转移 |
整数 |
| sentinel auth-pass <master-name> <password> |
主节点密码 | 自定义 |
| sentinel down-after-milliseconds <master-name> <milliseconds> |
节点不可达的判断时间 | 整数 |
| sentinel parallel-syncs <master-name> <numreplicas> |
新主节点出来后,同时有几个从节点进行复制操作 | 整数 |
| sentinel failover-timeout <master-name> <milliseconds> |
故障转移超时时间 | 整数 |
| sentinel notification-script <master-name> <script-path> |
配置脚本记录故障转移期间的事件 | 自定义 |
| sentinel client-reconfig-script <master-name> <script-path> |
配置脚本记录故障转移结束后的处理结果 | 自定义 |
如果想动态的调整配置,可通过如下命令
sentinel set <param> <value>
| 参数 | 使用方法 |
| quorum | sentinel set master1 quorum 2 |
| auth-pass | sentinel set master1 auth-pass password |
| down-after-milliseconds | sentinel set master1 down-after-milliseconds 1000 |
| parallel-syncs | sentinel set master1 parallel-syncs 1 |
| failover-timeout | sentinel set master1 failover-timeout 5000 |
| notification-script | sentinel set master1 notification-script /x.sh |
| client-reconfig-script | sentinel set master1 client-reconfig-script /y.sh |
在调整配置时需要注意以下几点:
- 只对当前调整的节点有效
- 配置调整成功会直接刷新配置文件
- 所有的哨兵节点配置最好是一致的
部署
拓扑结构
这里以1个主节点,3个从节点,4个哨兵节点来组成一个Redis Sentinel。
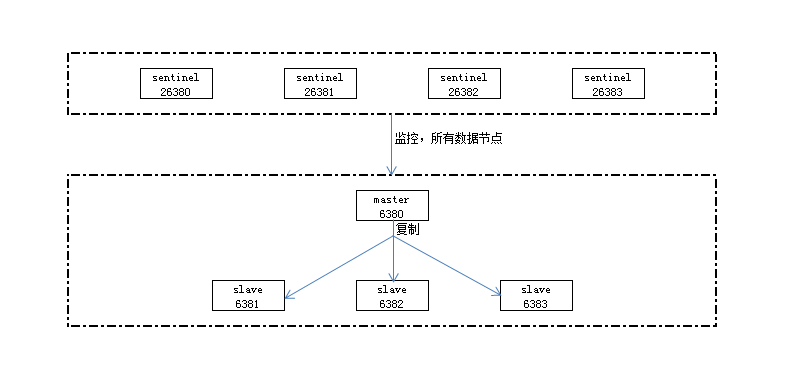
数据节点
主节点
主要配置如下:
#6380
#端口
port 6380
#守护进程
daemonize yes
#rdb文件
dbfilename "dump.rdb"
#工作目录
dir "./"
#日志文件
logfile "redis-server.log"
主节点启动
[root@vagrant redis-6380]# ./redis-server redis.conf
#检查服务状态
[root@vagrant redis-6380]# ps -ef|grep redis
root 4156 1 0 14:07 ? 00:00:00 ./redis-server *:6380
从节点
主要配置如下,增加了slaveof配置:
#6381,6382,6383
#端口
port 6381
#守护进程
daemonize yes
#rdb文件
dbfilename "dump.rdb"
#工作目录
dir "./"
#日志文件
logfile "redis-server.log"
#设置复制主节点
slaveof 127.0.0.1 6380
从节点启动
[root@vagrant redis-6381]# ./redis-server redis.conf
[root@vagrant redis-6382]# ./redis-server redis.conf
[root@vagrant redis-6383]# ./redis-server redis.conf
#检查服务状态
[root@vagrant redis-6383]# ps -ef|grep redis
root 4156 1 0 14:07 ? 00:00:00 ./redis-server *:6380
root 4164 1 0 14:13 ? 00:00:00 ./redis-server *:6381
root 4175 1 0 14:14 ? 00:00:00 ./redis-server *:6382
root 4183 1 0 14:15 ? 00:00:00 ./redis-server *:6383
主从关系
主节点视角:
[root@vagrant redis-6383]# ./redis-cli -p 6380 info replication
# Replication
role:master
connected_slaves:3
slave0:ip=127.0.0.1,port=6381,state=online,offset=210,lag=1
slave1:ip=127.0.0.1,port=6382,state=online,offset=210,lag=1
slave2:ip=127.0.0.1,port=6383,state=online,offset=210,lag=1
从节点视角:
[root@vagrant redis-6383]# ./redis-cli -p 6381 info replication
# Replication
role:slave
master_host:127.0.0.1
master_port:6380
master_link_status:up
哨兵节点
哨兵配置
#26380,26381,26382,26383
#端口
port 26380
#守护进程
daemonize yes
#工作目录
dir "./"
#日志文件
logfile "redis-sentinel.log"
#监控的主节点
sentinel monitor master1 127.0.0.1 6380 2
#节点不可达判断时间
sentinel down-after-milliseconds master1 1000
#同时向新主节点发起复制操作的节点个数
sentinel parallel-syncs master1 1
#故障转移超时时间
sentinel failover-timeout master1 5000
Tips:不要手动设置sentinel myid值,此值会自动生成
哨兵启动
[root@vagrant redis-6380]# ./redis-sentinel sentinel.conf
[root@vagrant redis-6381]# ./redis-sentinel sentinel.conf
[root@vagrant redis-6382]# ./redis-sentinel sentinel.conf
[root@vagrant redis-6383]# ./redis-sentinel sentinel.conf
配置变化
当哨兵节点都启动完成后,配置文件会被自动修改掉。
减少的配置:
sentinel parallel-syncs master1 1
增加的配置:
#最后的数字表示是第几次进行故障转移
sentinel config-epoch master1 0
sentinel leader-epoch master1 0
#自动发现3个从节点
sentinel known-slave master1 127.0.0.1 6382
sentinel known-slave master1 127.0.0.1 6383
sentinel known-slave master1 127.0.0.1 6381
#自动发现除自身的3个哨兵节点
sentinel known-sentinel master1 127.0.0.1 26381 29e2457f28a8fecd77f253b542f10523878c4e59
sentinel known-sentinel master1 127.0.0.1 26380 699c1928d7ebe3b9f3a8395e824313e1e8f66a7e
sentinel known-sentinel master1 127.0.0.1 26382 8b1933d36031e2b9ee581f8269ac4bd427bb6063
sentinel current-epoch 0
哨兵确认
检查哨兵的状态是否与配置的一致
[root@vagrant redis-6383]# ./redis-cli -p 26380 info sentinel
# Sentinel
sentinel_masters:1
sentinel_tilt:0
sentinel_running_scripts:0
sentinel_scripts_queue_length:0
sentinel_simulate_failure_flags:0
master0:name=master1,status=ok,address=127.0.0.1:6380,slaves=3,sentinels=4
API
哨兵节点作为一个特殊的redis节点,有如下一些专属的api
sentinel masters
查看所有被监控的主节点信息
[root@vagrant redis-6383]# ./redis-cli -p 26380 sentinel masters
1) 1) "name"
2) "master1"
3) "ip"
4) "127.0.0.1"
5) "port"
6) "6382"
...
sentinel master
查看某个主节点的信息
[root@vagrant redis-6383]# ./redis-cli -p 26380 sentinel master master1
1) "name"
2) "master1"
3) "ip"
4) "127.0.0.1"
5) "port"
6) "6382"
...
sentinel slaves
查看某个主节点下从节点的信息
[root@vagrant redis-6383]# ./redis-cli -p 26380 sentinel slaves master1
1) 1) "name"
2) "127.0.0.1:6380"
3) "ip"
4) "127.0.0.1"
5) "port"
6) "6380"
...
2) 1) "name"
2) "127.0.0.1:6381"
3) "ip"
4) "127.0.0.1"
5) "port"
6) "6381"
...
3) 1) "name"
2) "127.0.0.1:6383"
3) "ip"
4) "127.0.0.1"
5) "port"
6) "6383"
...
sentinel sentinels
查看某个主节点下哨兵的信息,不包括当前使用哨兵
[root@vagrant redis-6383]# ./redis-cli -p 26380 sentinel sentinels master1
1) 1) "name"
2) "f1b42cce7da99809b392a51b366cde7b3b6f6048"
3) "ip"
4) "127.0.0.1"
5) "port"
6) "26383"
...
2) 1) "name"
2) "8b1933d36031e2b9ee581f8269ac4bd427bb6063"
3) "ip"
4) "127.0.0.1"
5) "port"
6) "26382"
...
3) 1) "name"
2) "29e2457f28a8fecd77f253b542f10523878c4e59"
3) "ip"
4) "127.0.0.1"
5) "port"
6) "26381"
sentinel get-master-addr-by-name
查看某个主节点的ip与port信息
[root@vagrant redis-6383]# ./redis-cli -p 26380 sentinel get-master-addr-by-name master1
1) "127.0.0.1"
2) "6382"
sentinel reset
重置匹配主节点的配置,清除主节点的相关状态(例如故障转移),重新发现从节点和哨兵节点
[root@vagrant redis-6383]# ./redis-cli -p 26380 sentinel reset master1
(integer) 1
sentinel failover
对主节点进行强制故障转移
[root@vagrant redis-6383]# ./redis-cli -p 26380 sentinel failover master1
OK
sentinel ckquorum
检查当前的可达哨兵节点数是否达到quorum个数,如果达不到则无法进行故障转移
[root@vagrant redis-6383]# ./redis-cli -p 26380 sentinel ckquorum master1
OK 4 usable Sentinels. Quorum and failover authorization can be reached
sentinel flushconfig
将哨兵节点的配置更新到磁盘
[root@vagrant redis-6383]# ./redis-cli -p 26380 sentinel flushconfig
OK
sentinel remove
取消当前哨兵节点对某个主节点的监控
[root@vagrant redis-6383]# ./redis-cli -p 26380 sentinel remove master1
OK
sentinel monitor
对当前哨兵节点添加对某个主节点的监控
[root@vagrant redis-6383]# ./redis-cli -p 26380 sentinel monitor master1 127.0.0.1 6381 2
OK
sentinel set
动态修改哨兵的配置,只对当前哨兵生效。修改成功后会立即更新配置文件,不同于redis.conf需要执行config rewrite。
[root@vagrant redis-6380]# ./redis-cli -p 26380 sentinel set master1 quorum 3
OK
sentinel is-master-down-by-addr
Sentinel节点之间用来交换对主节点是否下线的判断,根据参数的不同,还可以作为Sentinel领导者选举的通信方式
原理
定时监控任务
1.间隔10s
每个sentinel通过主从节点获取info信息,更新拓扑结构。主要作用如下:
- 通过主节点获取从节点信息,sentinel节点不需要显式配置从节点的原因
- 自动感知新加入的从节点
- 节点不可达或故障转移后,更新最新的拓扑信息
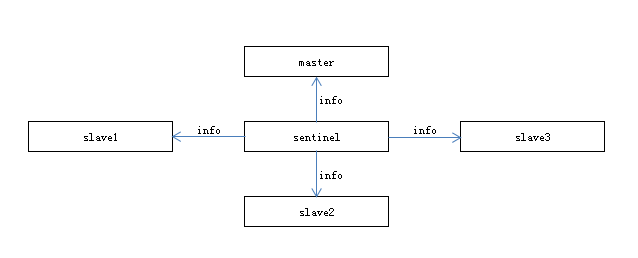
2.间隔2s
每个sentinel节点向所有redis数据节点的__sentinel__:hello频道发送该sentinel节点的信息及主节点的信息,同时也订阅所有数据节点上的__sentinel__:hello频道来获取其他sentinel节点的信息与主节点信息。主要作用如下:
- 发现新的sentinel节点,与它们建立连接
- sentinel节点之间交换主节点的状态,用于客观下线以及领导者选举的判断
#接收到的消息
[root@vagrant redis-6383]# ./redis-cli -p 6381 subscribe __sentinel__:hello
Reading messages... (press Ctrl-C to quit)
1) "subscribe"
2) "__sentinel__:hello"
3) (integer) 1
1) "message"
2) "__sentinel__:hello"
3) "127.0.0.1,26381,29e2457f28a8fecd77f253b542f10523878c4e59,7,master1,127.0.0.1,6381,7"
1) "message"
2) "__sentinel__:hello"
3) "127.0.0.1,26382,8b1933d36031e2b9ee581f8269ac4bd427bb6063,7,master1,127.0.0.1,6381,7"
1) "message"
2) "__sentinel__:hello"
3) "127.0.0.1,26383,f1b42cce7da99809b392a51b366cde7b3b6f6048,7,master1,127.0.0.1,6381,7"
1) "message"
2) "__sentinel__:hello"
3) "1.1.1.1,26380,699c1928d7ebe3b9f3a8395e824313e1e8f66a7e,7,master1,127.0.0.1,6381,7"
<Sentinel节点IP> <Sentinel节点端口> <Sentinel节点runId> <Sentinel节点配置版本><主节点名字> <主节点Ip> <主节点端口> <主节点配置版本>
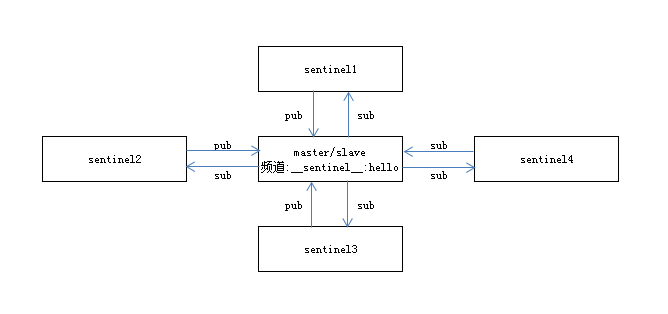
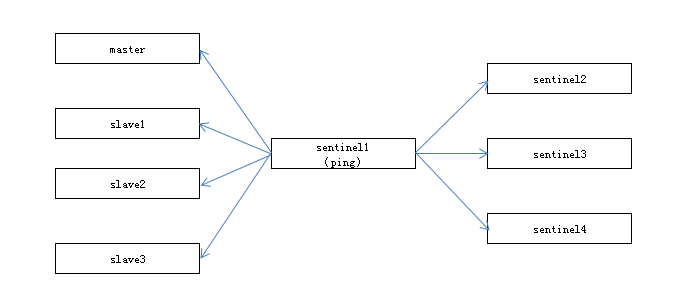
3.间隔1s
每个sentinel节点会向主节点、从节点、其余sentinel节点发送一条ping命令做一次心跳检测,来确认这些节点当前是否可达。
主观下线与客观下线
主观下线
当sentinel每隔1秒对主节点、从节点、其他sentinel节点发送ping命令做心跳检测时,如果这些节点超过down-after-milliseconds没有进行有效回复,sentinel节点就认为此节点主观下线。
客观下线
当主观下线的节点为主节点时,sentinel会向其他sentinel节点发送sentinel ismaster-down-by-addr命令来获取其他sentinel节点对主节点的判断,如果超过quorum个sentinel节点认为主节点为主观下线,则sentinel会认为主节点为客观下线。
命令说明:sentinel is-master-down-by-addr {ip} {port} {current_epoch} {runid}
- ip:主节点ip
- port:主节点端口
- current_epoch:当前配置纪元
- runid:”*“交换对主节点下线的判定,否则当runid等于当前Sentinel节点的runid时,作用是当前Sentinel节点希望目标Sentinel节点同意自己成为领导者的请求
[root@vagrant redis-6383]# ./redis-cli -h 127.0.0.1 -p 26380 sentinel is-master-down-by-addr 127.0.0.1 6381 7 '*'
1) (integer) 0
2) "*"
3) (integer) 0
返回结果说明:
- down_state:目标Sentinel节点对于主节点的下线判断,1是下线,0是在线
- leader_runid:当leader_runid等于“*”时,代表返回结果是用来做主节点是否不可达判断的,当leader_runid等于具体的runid,代表目标节点同意runid成为领导者
- 领导者纪元
sentinel leader选举
实际完成故障转移只需要一个sentinel节点,redis使用了raft算法来实现leader的选举,基本上最先完成客观下线的节点就是leader,大致过程如下:
- 每个在线的Sentinel节点都有资格成为领导者,当它确认主节点主观下线时候,会向其他Sentinel节点发送sentinel is-master-down-by-addr命令,要求将自己设置为领导者
- 收到命令的Sentinel节点,如果没有同意过其他Sentinel节点的sentinelis-master-down-by-addr命令,将同意该请求,否则拒绝
- 如果该Sentinel节点发现自己的票数已经大于等于max(quorum,num(sentinels)/2+1),那么它将成为领导者
- 如果此过程没有选举出领导者,将进入下一次选举
故障转移
sentinel leader执行故障转移的大致流程如下:
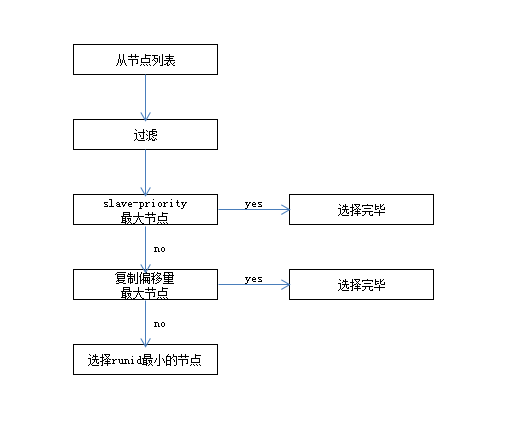
1.在从节点中选出一个节点作为新的主节点
- 过滤:“不健康”(主观下线、断线)、5秒内没有回复过Sentinel节点ping响应、与主节点失联超过down-after-milliseconds*10秒
- 选择slave-priority(从节点优先级)最高的从节点列表,如果存在则返回,不存在则继续
- 选择复制偏移量最大的从节点(复制的最完整),如果存在则返回,不存在则继续
- 选择runid最小的从节点
2.sentinel leader对选出来的节点执行slaveof no one让其变为主节点
3.sentinel leader向剩余的从节点发送命令,让它们成为新主节点的从节点,复制规则和parallel-syncs参数有关
4.sentinel节点集合会将原来的主节点更新为从节点,并保持着对其关注,当其恢复后命令它去复制新的主节点