介绍redis的主从复制
前言
为了提高缓存服务器的并发处理量可使用redis的主从复制特性,来实现负载均衡。
准备工作
由于机器的限制,此文章中的redis实例都是在一台机器上启动的,通过不同的port来模拟不同的redis实例。
[root@iZwz9i8fd8lio2yh3oerizZ redis-6383]# ps -ef|grep redis
root 11946 1 0 Sep15 ? 00:35:48 ./redis-server 127.0.0.1:6379
root 23867 1 0 16:45 ? 00:00:00 ./redis-server 127.0.0.1:6381
root 23972 1 0 16:49 ? 00:00:00 ./redis-server 127.0.0.1:6382
root 24000 1 0 16:51 ? 00:00:00 ./redis-server 127.0.0.1:6383
配置
复制建立
redis实例默认都是主节点,每个从节点只能有一个主节点,而主节点可以有多个从节点,复制的数据只能从主节点到从节点。可通过如下方式配置:
- 配置文件:在redis.conf中增加
slaveof {master-host} {master-port}的配置,启动服务时自动生效 - 服务启动:在执行redis-server命令启动服务时,增加
--slaveof {master-host} {master-port}的参数 - 命令使用:在启动服务后,进入实例执行
slaveof {master-host} {master-port}生效
Tips:为了可维护性,线上环境一般都是使用配置文件的方式
将6382,6383配置为6381的从机,查看各实例的复制状态信息
#6381
127.0.0.1:6381> info replication
# Replication
role:master
connected_slaves:2
slave0:ip=127.0.0.1,port=6383,state=online,offset=168,lag=0
slave1:ip=127.0.0.1,port=6382,state=online,offset=168,lag=1
#6382
127.0.0.1:6382> info replication
# Replication
role:slave
master_host:127.0.0.1
master_port:6381
#6383
127.0.0.1:6383> info replication
# Replication
role:slave
master_host:127.0.0.1
master_port:6381
在主节点设置了键值对后,可在从节点获取
[root@iZwz9i8fd8lio2yh3oerizZ redis-6383]# ./redis-cli -p 6381 set a 11
OK
[root@iZwz9i8fd8lio2yh3oerizZ redis-6383]# ./redis-cli -p 6382 get a
"11"
[root@iZwz9i8fd8lio2yh3oerizZ redis-6383]# ./redis-cli -p 6383 get a
"11"
复制断开
如果希望某个从节点,不再归属于某个主节点,可使用slaveof no one命令,命令处理流程:
- 断开与主节点的复制关系
- 从节点提升为主节点,数据保留
#断开6383的复制
[root@iZwz9i8fd8lio2yh3oerizZ redis-6383]# ./redis-cli -p 6383 slaveof no one
OK
#6383复制状态
[root@iZwz9i8fd8lio2yh3oerizZ redis-6383]# ./redis-cli -p 6383 info replication
# Replication
role:master
connected_slaves:0
#6381复制状态
[root@iZwz9i8fd8lio2yh3oerizZ redis-6383]# ./redis-cli -p 6381 info replication
# Replication
role:master
connected_slaves:1
slave0:ip=127.0.0.1,port=6382,state=online,offset=2780,lag=1
如果想切换某个从节点到新的主节点,可使用{master-host} {master-port}命令,命令处理流程:
- 断开与旧主节点的复制关系
- 与新主节点建立复制关系
- 删除从节点上的所有数据
- 从新主节点复制数据
#6383旧值
[root@iZwz9i8fd8lio2yh3oerizZ redis-6379]# ./redis-cli -p 6383 get a
"11"
#复制新主节点
[root@iZwz9i8fd8lio2yh3oerizZ redis-6379]# ./redis-cli -p 6383 slaveof 127.0.0.1 6379
OK
#新值
[root@iZwz9i8fd8lio2yh3oerizZ redis-6379]# ./redis-cli -p 6383 get a
"100"
#复制状态
#6379
[root@iZwz9i8fd8lio2yh3oerizZ redis-6379]# ./redis-cli -p 6379 info replication
# Replication
role:master
connected_slaves:1
slave0:ip=127.0.0.1,port=6383,state=online,offset=276,lag=1
#6383
[root@iZwz9i8fd8lio2yh3oerizZ redis-6379]# ./redis-cli -p 6383 info replication
# Replication
role:slave
master_host:127.0.0.1
master_port:6379
安全性
当出于安全考虑对主节点通过requirepass设置密码后,从节点如果想复制主节点需要设置masterauth为主节点的密码。
只读
由于数据复制只能从主节点到从节点,在从节点上的的任何修改都不会影响主节点,而且会造成主从节点的数据不一致,所以从节点一般都是配置为只读的slave-read-only=yes。
传输延迟
在线上环境时,主从节点一般部署在不同的机器上,所以需要考虑网络延迟问题,redis中的repl-disable-tcp-nodelay配置用于控制是否关闭TCP_NODELAY,默认为关闭状态:
- 关闭:主节点产生的命令数据无论大小都会及时地发送给从节点,这样主从之间延迟会变小,但增加了网络带宽的消耗。适用于主从之间的网络环境良好的场景,如同机架或同机房部署
- 开启:主节点会合并较小的TCP数据包从而节省带宽。默认发送时间间隔取决于Linux的内核,一般默认为40毫秒。这种配置节省了带宽但 增大主从之间的延迟。适用于主从网络环境复杂或带宽紧张的场景,如跨机房部署
拓补
redis的复制结构可以支持单层或多层复制关系,一般可分为如下3种
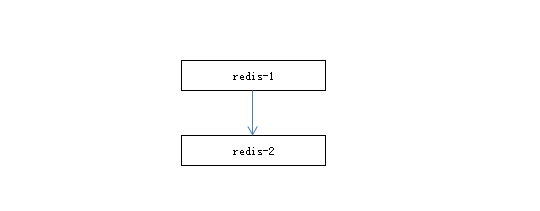
一主一从
最简单的复制拓补结构,一般用途:
- 主节点故障转移
- 主节点关闭持久化,从节点开启持久化,提高主节点的性能
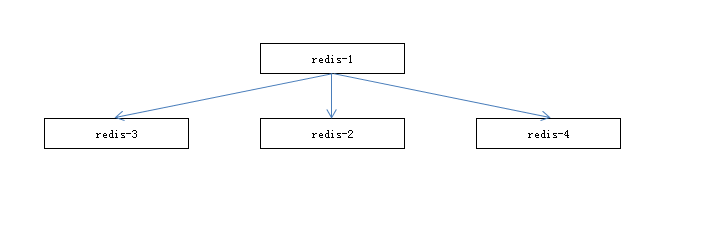
一主多从
最常用的复制拓补结构,一般用途:
- 主节点故障转移
- 读写分离,降低主节点压力
- 在从节点执行如:keys,sort等耗时命令
Tips:如果主节点的从节点过多且主节点的写并发较多的情况下,会过度消耗网络带宽与影响主节点的性能,线上环境一般2-3个从节点。
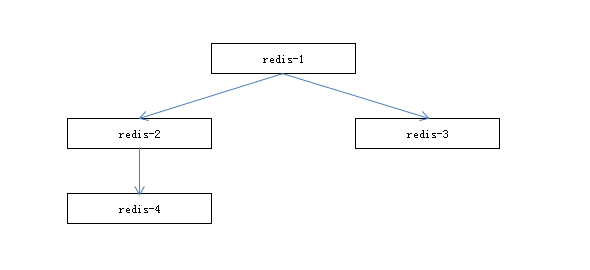
树状主从
比较复杂的复制拓补结构,一般用途:
- 从节点数量较多,通过从节点将数据向别的从节点复制,提高原始主节点的性能
#原始主节点6381
role:master
connected_slaves:1
slave0:ip=127.0.0.1,port=6382,state=online,offset=12855,lag=1
#从节点6382复制6381
role:slave
master_host:127.0.0.1
master_port:6381
master_link_status:up
master_last_io_seconds_ago:5
master_sync_in_progress:0
slave_repl_offset:12659
slave_priority:100
slave_read_only:1
connected_slaves:1
slave0:ip=127.0.0.1,port=6383,state=online,offset=12659,lag=0
#从节点6383复制6382
role:slave
master_host:127.0.0.1
master_port:6382
#验证数据
[root@iZwz9i8fd8lio2yh3oerizZ redis-6382]# ./redis-cli -p 6381 set c 88
OK
[root@iZwz9i8fd8lio2yh3oerizZ redis-6382]# ./redis-cli -p 6382 get c
"88"
[root@iZwz9i8fd8lio2yh3oerizZ redis-6382]# ./redis-cli -p 6383 get c
"88"
原理
复制过程
复制过程可分为如下6步:
- 保存主节点信息:还没建立复制流程,主节点连接状态为下线(master_link_status:down)
- 主从建立socket连接:每秒运行复制的定时任务,尝试与主节点建立socket连接,如果连接失败会记录失败日志
- 发送ping命令:检查主从socket是否可用,主节点当前是否可接受处理命令
- 权限验证:如果主节点设置了密码(requirepass),从节点需要配置(masterauth)
- 数据同步:主从连接成功后,主节点会把数据同步给从节点,是耗时最长的一步
- 命令持续复制:主节点会持续把写命令发送给从节点
数据同步
数据同步分为如下2种方式:
- 全量同步:当主从首次复制时,主节点会把全部数据一次性发给从节点,可能会对主从节点与网络造成较大的开销
- 部分同步:主要用于处理主从复制因网络闪断等原因造成的数据丢失,如果条件允许,当从节点重新连上主节点后,主节点只会发送丢失的数据,避免较大的网络开销
psync命令依赖的组件:
- 主从节点各自的复制偏移量:主节点为
master_repl_offset,从节点自身为slave_repl_offset与上报的为offset - 主节点复制积压缓冲区
- 主节点运行id
复制偏移量
主节点,处理完写入命令后会累加命令的字节长度master_repl_offset
# Replication
role:master
...
master_repl_offset:108
从节点每秒会向主节点上报自己的复制偏移量offset
# Replication
role:master
connected_slaves:1
slave0:ip=127.0.0.1,port=6382,state=online,offset=108,lag=0
从节点,收到主节点的写入命令后,会累加自身的偏移量slave_repl_offset
# Replication
role:slave
...
slave_repl_offset:108
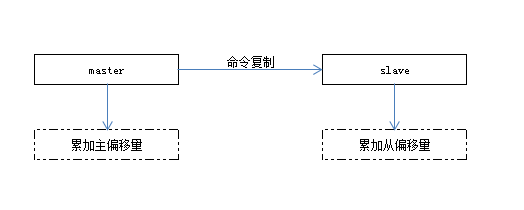
Tips:可通过复制偏移量来判断主从节点数据是否一致。如果master_repl_offset-slave_offset较大,则可能有网络延迟或命令阻塞需要进一步检查。
复制积压缓冲区
用于记录主节点的最近写入命令,可用于部分复制及复制命令丢失的补救
# Replication
role:master
...
#开启复制缓冲区
repl_backlog_active:1
#缓冲区最大长度
repl_backlog_size:1048576
#起始偏移量,计算当前缓冲区的可用范围
repl_backlog_first_byte_offset:1
#已保存数据的有效长度
repl_backlog_histlen:3120
通过上面的指标可计算获取,复制积压缓冲区内的可用偏移量范围[repl_backlog_first_byte_offset, repl_backlog_first_byte_offset+repl_backlog_histlen]。如果从节点的offset不在此范围内,在处理复制请求时,主节点会对从节点进行全量复制。
主节点运行id
redis实例的唯一识别id,可用于从节点识别复制的是哪个主节点,当id变化时就不能部分复制而需要使用全量复制了。
# Replication
role:master
...
master_replid:ee1821344611dbc7b6587b563246a22435422808
全量复制
在主从第一次建立复制关系时使用的是全量复制,大致流程如下:
- 发送psync命令进行数据同步,由于是第一次进行复制,从节点没有复制偏移量和主节点的运行ID,所以发送psync ? -1
- 主节点根据psync ? -1解析出当前为全量复制,回复+FULLRESYNC响应
- 从节点接收主节点的响应数据保存runid和偏移量offset
9845:S 03 Oct 15:29:46.742 * Trying a partial resynchronization (request 633fdc82b069b57678c1ae9aa4054220f7b7d334:1). 9845:S 03 Oct 15:29:46.743 * Full resync from master: a0326cdd26badbf2130d76095188c991494e7bbf:0 - 主节点执行bgsave保存RDB文件到本地
9869:M 03 Oct 15:29:46.742 * Starting BGSAVE for SYNC with target: disk 9869:M 03 Oct 15:29:46.743 * Background saving started by pid 9925 9925:C 03 Oct 15:29:46.746 * DB saved on disk 9925:C 03 Oct 15:29:46.747 * RDB: 0 MB of memory used by copy-on-write 9869:M 03 Oct 15:29:46.841 * Background saving terminated with success - 主节点发送RDB文件给从节点,从节点把接收的RDB文件保存在本地并直接作为从节点的数据文件
9845:S 03 Oct 15:29:46.842 * MASTER <-> SLAVE sync: receiving 202 bytes from master - 如果在从节点接受RDB数据期间,主节点又响应了写命令,这些命令会保存在复制客户端缓冲内,待从节点加载完RDB文件后,主节点再把缓冲区内的数据发给从节点
#对于主节点,当发送完所有的数据后就认为全量复制完成 9869:M 03 Oct 15:29:46.841 * Synchronization with slave 127.0.0.1:6382 succeeded - 从节点接收完主节点传送来的全部数据后会清空自身旧数据
9845:S 03 Oct 15:29:46.842 * MASTER <-> SLAVE sync: Flushing old data - 从节点清空数据后开始加载RDB文件,对于较大的RDB文件,这一
步操作依然比较耗时
9845:S 03 Oct 15:29:46.842 * MASTER <-> SLAVE sync: Loading DB in memory 9845:S 03 Oct 15:29:46.842 * MASTER <-> SLAVE sync: Finished with success - 从节点成功加载完RDB后,如果当前节点开启了AOF持久化功能,
它会立刻做bgrewriteaof操作
9845:S 03 Oct 15:29:46.843 * Background append only file rewriting started by pid 9926 9845:S 03 Oct 15:29:46.869 * AOF rewrite child asks to stop sending diffs. 9926:C 03 Oct 15:29:46.869 * Parent agreed to stop sending diffs. Finalizing AOF... 9926:C 03 Oct 15:29:46.869 * Concatenating 0.00 MB of AOF diff received from parent. 9926:C 03 Oct 15:29:46.869 * SYNC append only file rewrite performed 9926:C 03 Oct 15:29:46.870 * AOF rewrite: 0 MB of memory used by copy-on-write 9845:S 03 Oct 15:29:46.942 * Background AOF rewrite terminated with success
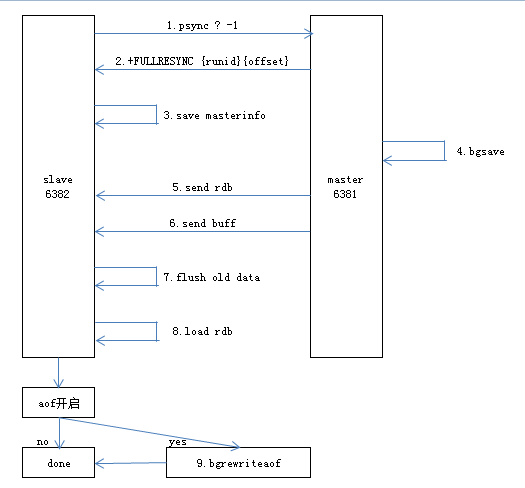
全量复制的主要开销如下:
- 主节点bgsave时间
- RDB文件网络传输时间
- 从节点清空数据时间
- 从节点加载RDB的时间
- 可能的AOF重写时间
Tips:如果主节点的数据量较大,开启新的从节点进行全量复制时,最好能挑选主节点压力比较小的时间来进行
2个复制缓冲区的区别,理解的不一定是对的:
- 复制积压缓冲区:当主从复制关系正常运转后,同步保存主节点发送给从节点的写命令,用于之后的主从节点的网络闪断的部分复制
- 复制客户端缓冲区:用于全量复制时,保存从节点接受RDB文件期间主节点产生的写命令
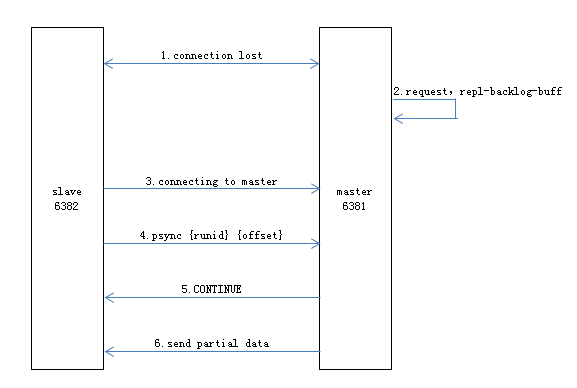
部分复制
当主从复制关系正常运转后,如果出现网络闪断等命令丢失情况时,从节点会向主节点要求补发丢失的数据,如果主节点的复制积压缓冲区内存在这部分数据则直接发送给从节点,这样就可以保持主从节点复制的一致性。大致流程如下:
- 当主从节点之间网络出现中断
- 主节点继续响应请求,保存最近的写命令到复制积压缓冲区(默认为1MB)
- 当主从节点网络恢复后,从节点会再次连上主节点
- 从节点向主节点发送pysnc{runid}{offset}命令,请求部分复制
- 主节点检查runid是否与自身一致且offset之后的数据是否在缓冲区内,检查成功返回+CONTINUE,告知从节点可部分复制
- 主节点根据偏移量把复制积压缓冲区里的数据发送给从节点
心跳
主从建立复制关系后,彼此之间通过长连接发送心跳命令来检查网络及服务是否正常。
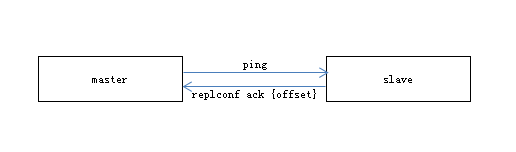
- 主从模拟成对方的客户端进行通信,client list查看信息,flags=M(主),flags=S(从)
- 主节点每隔repl-ping-slave-period(默认10秒)发送ping,检查从节点存活性与连接状态
- 从节点每隔1秒发送replconf ack{offset},上报复制偏移量检查复制数据是否丢失。主节点用来判断超时时间(info replication的lag参数),如果超过repl-timeout则认为从节点下线
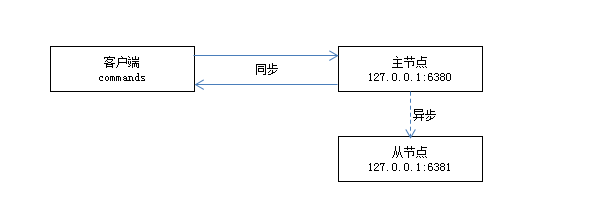
异步复制
主节点处理完客户端的写命令后,会直接返回给客户端,再异步将写命令发送给从节点,主从之间的数据可能会有延迟,正常情况下延迟在1秒内。如果需要查看延迟的字节量,可通过查看replication信息,master_repl_offset-slave_offset=延迟的字节量。
[root@vagrant redis-6380]# ./redis-cli -p 6382 info replication
# Replication
role:master
connected_slaves:2
slave0:ip=127.0.0.1,port=6381,state=online,offset=244823,lag=1
slave1:ip=127.0.0.1,port=6380,state=online,offset=244823,lag=1
master_repl_offset:244823
常见问题
读写分离
数据延迟
由于Redis复制数据的异步性,再加上网络带宽与命令阻塞的情况,在主节点写入数据后立即在从节点获取可能会获取不到数据。可尝试考虑如下方案:
- redis集群水平扩展,降低单集群的数据量,从而提高复制速度
- 定时监控主从偏移量差异,如果差异较大,redis客户端(需要代码控制,成本较大)控制暂时不使用某个从机,待偏移量减少后再使用
从节点故障
当某个从节点发生故障时,redis客户端(代码控制)需要能捕获,从而更换别的从节点进行服务的提供。
主从配置不一致
对于内存的配置或对内存会产生影响的配置,如maxmemory,hash-max-ziplist-entries等参数,必须要主从配置一致。其它的配置(如持久化策略)可按照实际情况,进行主从的差异化配置。
规避全量复制
如果redis产生全量复制且数据量比较大时则会非常消耗资源,以下是产生全量复制的场景,可以通过一些方法合理的处理。
第一次建立复制
第一次建立复制,不可避免的会进行一次全量复制,如果想为主节点添加从节点,最好在服务低峰的时间段进行。
节点运行ID不匹配
当从节点发现保存的主节点运行id与实际的主节点运行id不一致时,会进行全量复制。此情况一般是由于主节点故障重启后运行id发生改变产生,最好使用sentinel来进行故障的自动转移。
复制积压缓冲区不足
当主从间进行部分复制时,如果从机请求复制的偏移量已经不在主机的复制积压缓存区内时,就会变为全量复制。可根据主机每秒的偏移量增大数*网络中断时间,计算得到合理的缓冲区大小并进行设置。