介绍redis的内存相关优化。
内存消耗
1.内存使用统计
通过如下命令可获取redis实例的内存使用情况
127.0.0.1:6379> info memory
| 属性说明 | |
| used_memory:12597672 | redis的当前内存 |
| used_memory_human:12.01M | |
| used_memory_rss:17149952 | 系统显示的redis进程内存 |
| used_memory_rss_human:16.36M | |
| used_memory_peak:14492352 | redis的最大内存 |
| used_memory_peak_human:13.82M | |
| used_memory_peak_perc:86.93% | |
| total_system_memory:4018454528 | 系统内存 |
| total_system_memory_human:3.74G | |
| used_memory_lua:37888 | lua引擎内存 |
| used_memory_lua_human:37.00K | |
| maxmemory:1073741824 | 最大可用内存 |
| maxmemory_human:1.00G | |
| maxmemory_policy:noeviction | |
| mem_fragmentation_ratio:1.36 | 内存碎片率 used_memory_rss/used_memory |
| mem_allocator:jemalloc-4.0.3 | 内存分配器 |
需要特别注意内存碎片率:
- mem_fragmentation_ratio>1:说明存在内存碎片,如果比值很大则碎片率较严重,可重启实例解决
- mem_fragmentation_ratio<1:说明redis内存已超过系统内存,产生了磁盘交换,会导致redis的性能大幅下降
2.内存使用划分
redis的内存使用主要包括:自身内存,对象内存,缓冲内存,内存碎片
自身内存(used_memory)
一个空的redis,used_memory为800k左右,used_memory_rss在2M左右,也就是说redis自身占用的内存很小
对象内存(used_memory)
用于存储所有的数据,包括key与value,是占用内存最大的
缓冲内存(used_memory)
缓存内存包括:客户端缓冲、复制积压缓冲区、AOF缓冲区
内存碎片(used_memory_rss-used_memory)
redis默认使用的是jemalloc内存分配器,在64位系统下,会按照如下规则进行分配内存:
- 小:[8byte],[16byte,32byte,48byte,…,128byte],[192byte,256byte,…,512byte],[768byte,1024byte,…,3840byte]
- 大:[4KB,8KB,12KB,…,4072KB]
- 巨大:[4MB,8MB,12MB,…]
当为了存储5KB的对象时,会采用8KB的块存储,剩下的3KB就会变成碎片,而不能分配给其他对象使用。
下面的情况可能会出现较多的内存碎片:
- 频繁的更新操作,对已存在的键做append,setrange等更新操作
- 大量的键在过期后删除,释放的空间不能充分利用
可通过如下方式尝试解决:
- 数据对齐:在条件允许的情况做数据对齐,比如尽量采用数字类型或固定长度的字符串
- 安全重启:如果redis做了高可用,可重启碎片率较高的节点,注意保证服务的可用性
3.子进程内存消耗
子进程内存消耗主要是执行AOF/RDB重写时Redis创建的子进程内存消耗,理论上需要1倍的父进程内存来完成重写,但是因为Linux的写时复制技术(copy-on-write),子进程并不需要消耗1倍的父进程内存,但最好还是预留出一些内存(父进程内存的[0%-100%])用于子进程的重写操作,防止内存溢出。
如下设置可用于避免一些内存问题:
1.允许内核可以分配所有的物理内存,防止Redis进程执行fork时因系统剩余内存不足而失败
[root@DEV-HROEx64 mm]# sysctl vm.overcommit_memory=1
[root@DEV-HROEx64 redis]# vim /etc/sysctl.conf
2.关闭Linux的THP(Transparent Huge Pages)机制,此机制会导致copy-on-write期间复制内存页的单位从4KB变为2MB,如果父进程有大量写命令,会加重内存拷贝量,从而造成过度内存消耗
[root@DEV-HROEx64 mm]# echo never > /sys/kernel/mm/redhat_transparent_hugepage/enabled
[root@DEV-HROEx64 mm]# vim /sys/kernel/mm/redhat_transparent_hugepage
内存管理
1.服务器内存
一台单纯的redis服务器,内存使用主要包括如下几个部分:
- linux系统本身(1G)
- 其它一些服务进程(1G)
- redis主进程,可能有多个实例(剩余内存/实例个数+0.5)
- redis子进程(子进程执行过程中写入命令量,可粗略为单实例的50%)
上述数值只作为参考使用,具体配置需要结合实际情况。
Tips:如果单机部署多个实例,且实例都有持久化需求,需要避免多实例在同一时间进行持久化操作,防止内存溢出
2.内存上限
设置maxmemory的作用:
- 当缓存使用的内存超过maxmemory时,触发内存回收策略释放空间
- 防止内存超过物理内存,而产生磁盘交换,大幅降低redis的性能
根据1中的计算,可以得出可设置的maxmemory。
Tips:因为内存碎片的原因,此处的maxmemory=used_memory,而非used_memory_rss,所以要注意这部分是否会导致内存溢出
3.动态调整内存上限
使用如下命令,可用来为正在运行中的redis进程动态修改最大内存,以满足需求
127.0.0.1:6379> CONFIG set maxmemory 1G
4.内存回收策略
1.过期键删除
- 惰性删除:当客户端读取带超时属性的键时,如果键已过期则进行删除并返回空
- 定时任务删除:定时任务,默认每秒运行10次(config hz),回收过期键算法如下
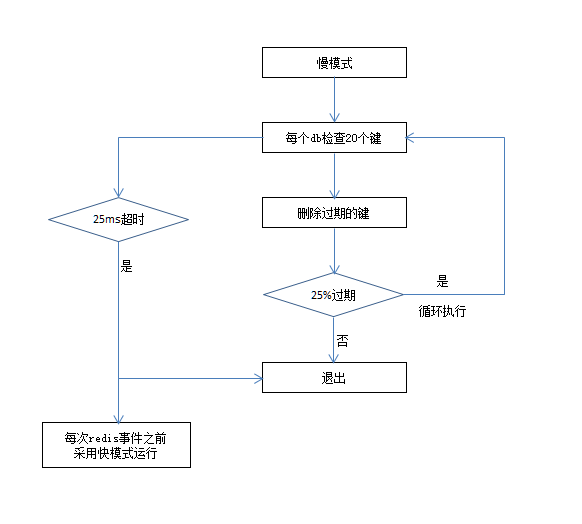
慢模式与快模式的内部执行逻辑相同,只是执行超时时间不同,慢模式为25ms超时,快模式为1ms且2秒内只能运行一次。
2.内存溢出控制策略
- noeviction:默认策略,不会删除任何数据,拒绝所有写入操作并返回客户端错误信息(error)OOM command not allowed when used memory,此时Redis只响应读操作
- allkeys-lru:根据LRU算法删除键,不管数据有没有设置超时属性,直到腾出足够空间为止
- allkeys-random:随机删除所有键,直到腾出足够空间为止
- volatile-lru:根据LRU算法删除设置了超时属性(expire)的键,直到腾出足够空间为止。如果没有可删除的键对象,回退到noeviction策略
- volatile-random:随机删除过期键,直到腾出足够空间为止
- volatile-ttl:根据键值对象的ttl属性,删除最近将要过期数据。如果没有,回退到noeviction策略
redis每次执行命令时都会尝试回收内存的操作,如果redis一直运行在(used_memory>maxmemory)且回收策略非(noeviction)的情况时,会频繁触发回收内存的操作,从而影响性能。
Tips:为了避免频繁回收内存产生的开销,redis最好工作在maxmemory>used_memory状态下
内存优化
1.redisObject对象
redis存储的数据都是使用redisObject对象进行封装的,包含如下属性:
| type | unsigned 4 | 0.5B | 对象的数据类型 | string、hash、list、set、zset |
| encoding | unsigned 4 | 0.5B | 对象的编码类型 | 对象在内部使用哪种数据结构 |
| lru | unsigned LRU_BITS(24) | 3B | LRU计时时钟 | 对象最后一次被访问的时间 |
| refcount | int | 4B | 引用计数器 | 对象被引用的次数,当为0时,可以安全回收当前对象空间 |
| *ptr | void(64位系统) | 8B | 数据指针 | 整数:直接存储数据 其它:指向数据的指针 |
Tips:当存储的值为字符串类型且长度<=44字节时,内部编码会使用embstr类型,字符串sds和redisObject一起分配,从而只要一次内存操作即可,在高并发常见如果能控制字符串长度可以提高性能
2.缩减键值对象
key
redis的key是使用string存储,需要占用存储空间,所以设计键时,在满足业务区分的情况下,尽量越短越好
value
- 精简业务信息,去除不必要存储的数据
- 将字符串进行压缩后存储
Tips:选用压缩工具时,需要综合考虑压缩速度和计算开销成本
3.共享对象池
redis内部维护了[0-9999]的整数对象池,当创建整数值对象或list、hash、set、zset的内部元素为整数值时可以直接使用对象池的整数对象,从而节约内存。
Tips:当设置maxmemory并启用LRU相关淘汰策略如:volatile-lru,allkeys-lru时,Redis禁止使用共享对象池;对于ziplist编码的值对象,也是不能使用共享对象池,因为ziplist使用压缩且内存连续,对象判断成本过高
为何只有整数对象池:
- 复用几率大
- 比较算法的时间复杂度为o(1),字符串为o(n),其他复杂数据结构如hash,list等需要o(n*n)
4.字符串优化
redis中所有键都是字符串类型,值对象除了整数都使用字符串存储。
字符串结构
redis的字符串结构为简单动态字符串(simple dynamic string),结构如下:
- len[int]:已用字节长度
- free[int]:未用字节长度
- buf[][char]:字节数组
sds字符串结构有如下特点:
- o(1)时间复杂度获取:字符串长度,已用长度,未用长度
- 保存字节数组,支持安全的二进制数据存储
- 内部实现空间预分配机制,降低内存再分配的频率
- 惰性删除机制,字符串缩减后的空间不释放,作为预分配空间保留
预分配机制
当对字符串进行append,setrange等修改操作时,会触发预分配机制,避免不断的重分配内存和字节数据复制,但同时会造成内存的浪费。空间预分配规则如下:
- 第一次创建len属性等于数据实际大小,free等于0,不做预分配
- 修改后如果已有free空间不够且数据小于1M,每次预分配一倍容量。如原有len=60byte,free=0,再追加60byte,预分配120byte,总占用空间:60byte+60byte+120byte+1byte
- 修改后如果已有free空间不够且数据大于1MB,每次预分配1MB数据。如原有len=10MB,free=0,当再追加100byte,预分配1MB,总占用空间:10MB+100byte+1MB+1byte
Tips:减少字符串的部分修改操作(append,setrange等),直接使用set来修改整个字符串,降低预分配带来的内存浪费与内存碎片率
字符串重构
不一定把每份数据作为字符串整体存储,像json这样的数据可以使用hash结构,使用二级结构存储也能帮我们节省内存。同时可以使用hmget、hmset命令支持字段的部分读取修改,而不用每次整体存取
5.编码优化
redis中类型与编码的对应关系如下:
| 类型 | 编码 | 数据结构 | 条件 |
| string | int | 整数编码 | 8个字节的长整型 |
| embstr | 优化内存分配的字符串编码 | 小于等于44个字节的字符串 | |
| raw | 动态字符串编码 | 大于44个字节的字符串 | |
| hash | ziplist | 压缩列表编码 | field个数<=hash-max-ziplist-entries(默认512) value最大空间(字节)<=hash-max-ziplist-value配置(默认64) |
| hashtable | 散列表编码 | 不满足ziplist条件 | |
| list | quicklist | 快速列表编码 ziplist组成的双向链表 |
list-max-ziplist-size(正数):节点ziplist最多包含的entry个数 list-max-ziplist-size(负数[-5 -1]):节点ziplist的字节大小 list-compress-depth:压缩深度(默认0,不压缩) |
| set | intset | 整数集合编码 | 元素都是整数 集合长度<=set-max-intset-entries(默认512) |
| hashtable | 散列表编码 | 不满足intset条件 | |
| zset | ziplist | 压缩列表编码 | field个数<=zset-max-ziplist-entries(默认128) value最大空间(字节)<=zset-max-ziplist-value配置(默认64) |
| skiplist | 跳跃表编码 | 不满足ziplist条件时 |
在了解了内部编码后,就可以通过调节条件参数来让redis使用对应的编码,从而减少内存,不过调整也不是随意的,需要慎重考虑。
Tips:编码类型的转换是写入redis数据时自动进行的,且转换只能从小内存编码往大内存编码进行。
6.控制键的数量
当redis中存在大量的键时,也会消耗内存,可以根据业务情况,利用redis中hash等数据结构,进行二级存储,降低外层键数量,从而节省内存。
在进行此类优化时,需要注意如下情况:
- hash编码必须调整为使用ziplist,ziplist长度控制在1000内,存储的对象需要为小对象,预估键规模设计hash的分组规模
- hash重构后键不能使用超时(expire)与淘汰(lru)机制自动删除,需要手动维护